Artificial intelligence (AI) is contributing to the transformation of a large number of sectors, from suggesting a song to analyzing our health status via a watch, along with manufacturing industry. One hindrance on this transformation relates to the overall complexity of AI systems, which often poses challenges in terms of transparency and comprehensions of the results delivered. In this context, the AI’s explanatory capability (or “explainability”) is referred as the ability to make their decisions and actions understandable to users – which is known as eXplainable AI (XAI); this is something crucial to generate trust and ensure a responsible adoption of these technologies.
Explainable AI (XAI); the ability to make their decisions and actions understandable to users
A wide range of technological solutions are currently being investigated in order to improve the explainability of AI algorithms. One of the main strategies includes the creation of intrinsically explainable models (ante hoc explanations). This type of models, such as decision trees and association rules, are designed to be transparent and comprehensible by their own nature. Their logical structure allows users to seamlessly follow the reasoning behind the AI-based decisions. Tools for visualization of AI explanations are key, since they represent graphically the decision-making process performed by the model, thus facilitating user comprehension. These tools might take different forms, such as dedicated dashboards, augmented reality glasses, or natural language explanations (as speech or as text).
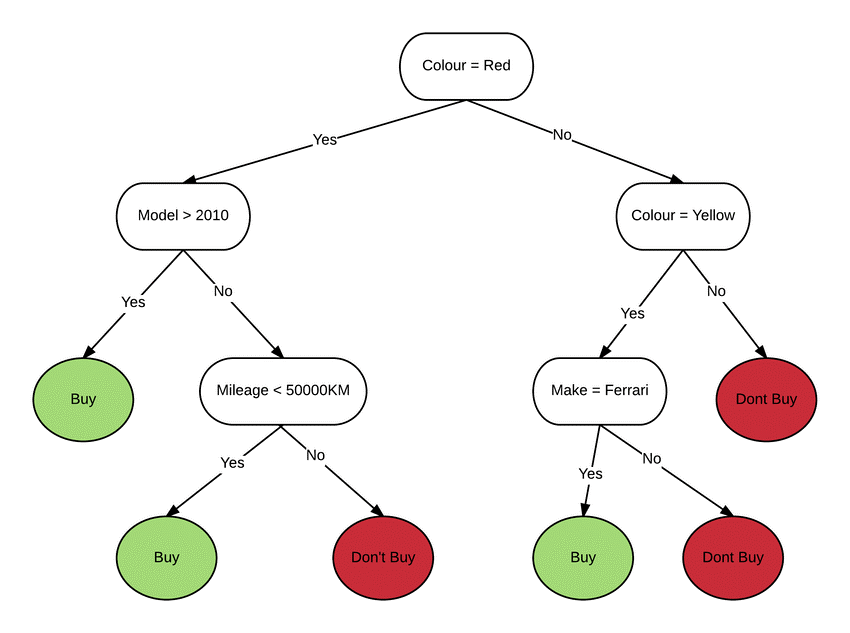
Intrinsically explainable system: decision tree. The intermediary nodes are conditions that are progressively verified until reaching the final result
Natural Language explanations for a recommender system of new routes for exercising. Extracted from Xu et al. (2023). XAIR: framework of XAI in augmented reality.
Another commonly used family of explanation techniques is called post hocmethods: these consist in, once the AI model has been created and trained, a posteriori processing and analyzing this resulting model to provide explanations of the results. For example, some of these techniques evaluate how much is contributed by each input variable in the final result of the system (sensibility analysis). Among post hoc explainability techniques, SHAP (Shapley Additive exPlanations), a method based on cooperative game theory, allows to extract coefficients that determine the importance of each input variable on the final result of an AI algorithm.
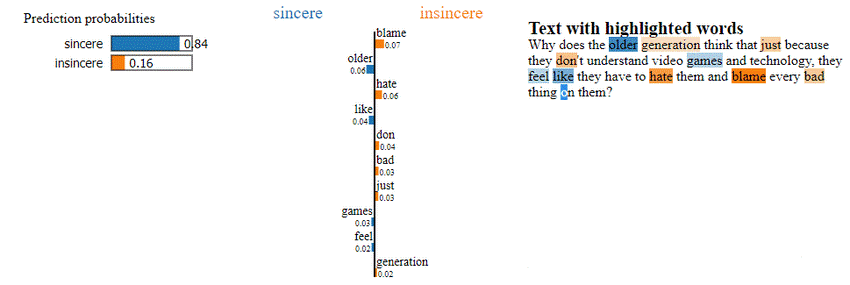
Other XAI techniques include decomposition, which divides the AI model into simpler and more easily explainable components, and knowledge distillation into surrogate models, which approximate the function of the original system while being more easily comprehensible. On the other hand, the so-called “local explanations” consist in methods that explain individual examples (input-output), not the entire AI model. An example are the explanations provided by tools such as LIME (Local Interpretable Model-agnostic Explanations). As an illustration of LIME, the example in the following figure shows a specific inference in text classification task, in which a text is classified as “sincere” (with 84% of likelihood), and the most relevant words for that decision are highlighted, as an explanation of this individual classification [Linardatos et al. (2020)].
An additional approach for XAI relates to the integration of input by users in the process of AI model construction, which is known in general as “Human-in-the-Loop” (HITL). This approach allows users to interact (e.g. by labelling new data) and to supervise the AI algorithm building process, adjusting its decisions in real time and thus improving the overall system transparency.
At CARTIF, we are actively working in different projects related with AI, such as s-X-AIPI to help advance in the explainability of AI systems used in industrial applications. A significant example in our work are dashboards (visualization or control panels) designed for the supervision and analysis of the performance of fabrication processes studied in the project. These dashboards allow plant operators to visualize and understand in real time the actual status of the industrial process.
Predictive and anomaly detection models have been created in the context of asphalt industrial processes which not only anticipate future values, but also detect unusual situations in the asphalt process and explain the factors that have an influence on these predictions and detections. Thus, this helps operators make adequate informed decisions and better understand the results generated by the AI systems and how to take proper actions.
Explainability in AI methods is essential for the safe and effective AI adoption in all types of sectors: industry, retail, logistics, pharma, construction… In CARTIF, we are committed with the development of technologies to create AI-based applications that do not only improve processes and services, but also are transparent and comprehensible for users; in short, that are explainable.
Co-author
Iñaki Fernández.PhD in Artificial Intelligence. Researcher at the Health and Wellbeing Area of CARTIF.
Digital twin has become one of the main trends or “mantras” in relation to digitalisation. It is practically a synonym of a product, something that you can buy as a commodity for a company. At CARTIF, we believe that the digital twin concept is a synonym of the Industry 4.0 paradigm, a “revolutionary” approach that has transformed the way we conceive and manage industrial processes.
The term “digital twin” was created by John Vickers of NASA in 2010, but its predecessor, the product lifecycle, was introduced by Michael Grieves in 2002. This philosophy focused on managing a product throughout its life, from creation to its disposal. In essence, the physical product generates data that feeds a virtual space, providing essential information for decision-making and optimisation of the actual object.
A definition of a digital twin could be “An accurate and complete digital representation of physical objects, processes or systems with real-time data and physical characteristics, behaviours and relationships”
A key questions is why do we need Digital Twins? In other words, what is their utility? These accurate, real-time digital representations offer a number of key advantages:
Data compilation and analysis to obtain valuable information and generate knowledge, driving efficiency and informed decision-making.
Accurate and dynamic simulation of the behaviour of physical objects, enabling virtual testing and experimentation before implementing changes, like risky investments, in the real world.
Reducing costs and risks by minimisong risk and accelerating innovation in a wide range of sectors, from manufacturing to healthcare.
Real-time update on a ongoing basis as new data is collected from the physical object, ensuring its validity along its lifecycle.
Like previous industrial revolutions, Industry 4.0 has transformed the way we work. This fourth revolution focuses on the interconnection of systems and processes to achieve greater efficiency throughout the value chain. The factory is no longer an isolated entity, but a node in a global production network.
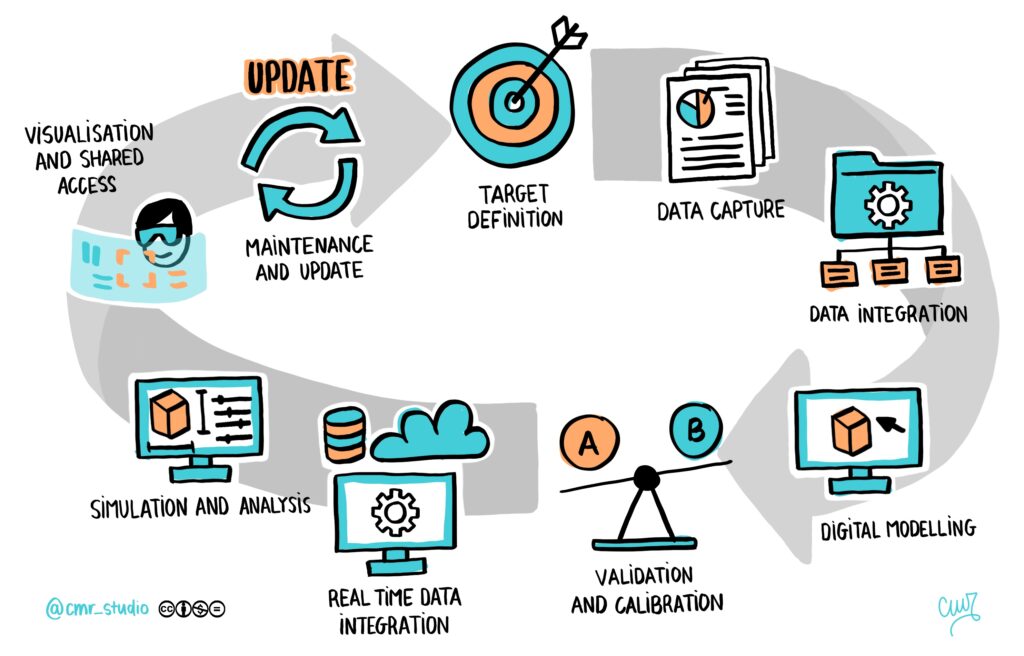
To create an effective Digital Twin, at CARTIF we follow a systematic recipe of 9 steps:
Objective definition: we identify the physical object, process or system we want to replicate and we clearly understand its purpose and objectives,
Data compilation: we gather all relevant data from the physical object using IoT sensors, historical records or other sources of information.
Data integration: we organise and combine the collected data in a suitable format for processing and analysis.
Modelling and construction: we use different simulation and modelling technologies to create and accurate digital representation of the physical object.
Validation and calibration: we verify and adjust the digital twin model using reference data and comparative tests with the real physical object.
Real-time integration: we establish a real-time connection between the digital twin and the IoT sensors of the physical object to link real-time data.
Analysis and simulation: we use the digital twin to make analysis, simulations and virtual tests of the physical object.
Visualisation and shared Acces: we provide visual interfaces and shared access tools for users to interact with the digital twin.
Maintenance and upgrade: we keep the digital twin up to date through real-time data collection, periodic calibration and incorporation of improvements and upgrades.
Just a previous industrial revolutions required enabling technologies, Industry 4.0 needs its own digital enablers. As we said at the beginning, we consider the digital twin a digitised form of the Industry 4.0 paradigm because digital enablers are fundamental to creating digital twins effectively. At CARTIF, we have accumulated almost 30 years of experience applying these technologies in various sectors, from industry to healthcare.
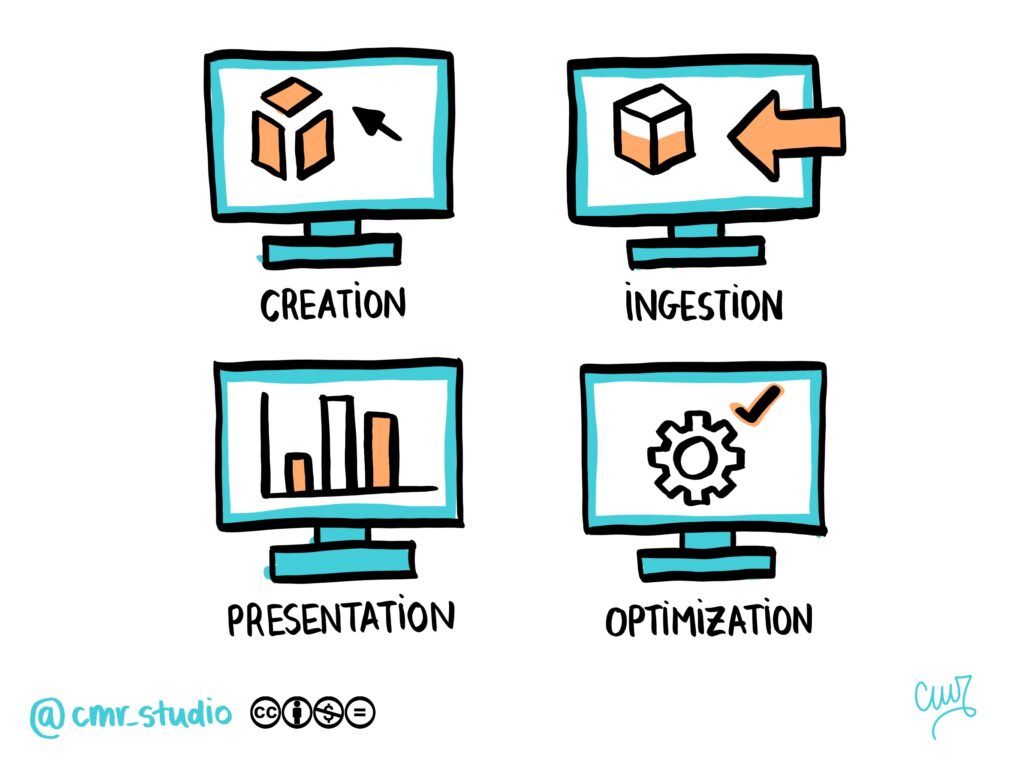
Digital enabling technologies fall into four main categories:
Creation Technologies: these technologies allow the creation of Digital Twins using physical equations, data, 3D modelling or discrete events.
Optimisation: optimisation is achieved through methods such as linear or non-linear programming, simulations, AI algorithms and heuristic approaches.
Presentation: the information generated can be presented through commercial solutions, open source tools such as Grafana or Apache superset ot even augmented reality visualisations.
Despite current progress, the challenge of keeping Digital Twins up to date remains an area of ongoing development. Automatic updating to reflect reality is a goal that requires significant investment in research and development.
In short, Digital Twins are the heart of Industry 4.0, boosting efficiency and informed decision-making. At CARTIF, we are committed to continuing to lead the way in this exciting field, helping diverse industries embrace the digital future.
The common denominator of artificial intelligence is the need of available, good qualilty and real data to advance in the different procedures needed to create and train the models. Practical research in AI often lacks available and reliable datasets so the practitioners can try different AI algortihms to solve different problems.
In some industrial research fields like predictive maintenance is particularly challenging in this aspect as many researchers do not have access to full-size industrial equipment or there are not available datasets representing a rich information content in different evolutions of faults that can happen to an asset or machine. In addition to that, the available datasets are clearly unbalances as the norm for machines is that they operate properly and only few examples of faults appear during their lifetime.
It´s very important from the AI research point of view the availability of reliable and interesting data sources that can provide a variety of examples to test different signal processing algorithms and introduce students and researchers into practical application such as signal processing, classification or prediction.
The ideal situation for researchers and developers of artificial intelligence solutions is that everyone, to a certain extent, shares data. But sharing data cannot be seen only as a way to help other people, sharing research data can bring many advantages to the data donor:
It´s part of good data practice and open science as it is encouraged to make data accesible together with the scientific papers generated.
Cut down on academic fraud and prevent publications of studies based on fake data.
Validate results. Anyone can make a mistake, if we share the data we used, other researchers could replicate our work and detect any potential error in our work.
More sicentific breakthroughs. This is especially true in social and health science where data sharing would enable for example more studies in human brain as Alzheimer´s Disease and many others.
A citation advantage. Studies that make data available in a public repository are more likely to receive more citations than similar studies for which the data is not made available.
Best teaching tools based on real cases.
At Europe level the European Commission has launched the Open Research Europe, a scientific publishing service, for Horizon 2020 and Horizon Europe beneficiaries with a service to publish their results in full compliance with commission open access policies. The service provides an easy, high quality peer-reviewed venue to publish their results in open access, at no cost to them. Other interesting service part of this open research initiative is Zenodo, an open repository to upload your research results. In addition to the open research publishing guidelines, data guidelines are also available which adheres the F.A.I.R principles too and refers a number of trusted repositories like Zenodo, that we are obliged to use based on the European project rules.
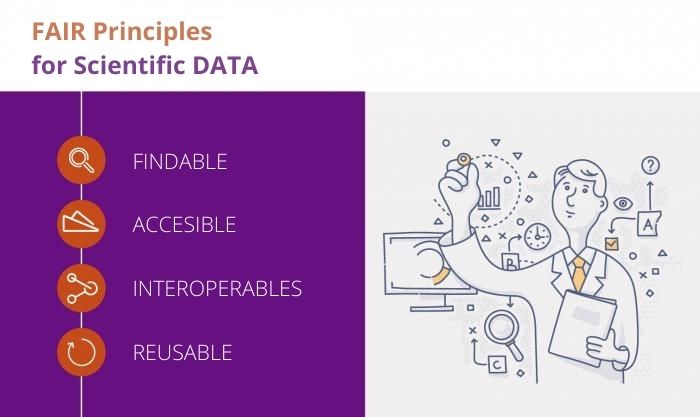
The FAIR guiding principles for publishing data mean that the data and its meta-data that defines it must be:
Findable: (meta)data are assigned a globally unique and persistent identifier.
Accessible: (meta)data are retrievable by their identifier using a standardized communications protocol.
Interoperable: (meta)data use a formal, accessible, shared, and broadly applicable language for knowledge representation.
Reusable: meta(data) are richly described with a plurality of accurate and relevant attributes.
Besides, from the governmental point of view European Commission, both European Data Strategy and Data Governance policy are powerful initiatives focus on the implementation of European data spaces, among which the Commission proposes the creation of a specific European industrial (manufacturing) data space to take advantages of the strong European industrial base and improve their competitiveness.
As researchers in CARTIF, we are committed to promote such openness with our research projects. For example, for CAPRI project it has been recently created its own Zenodo channel repository, where we periodically upload project results of the advanced solutions we are developing for the process industry such as cognitive sensors or cognitive control algorithms. You can go to the repository and inspect more than 40 datsasets, sourcecode or videos we already have uploaded.
Researchers are increasingly confronted with situations of “digitalise” something that has not been digitalised before, temperatures, pressures, energy consumes,etc. for these cases we look for measure systems or a sensor in a commercial catalogue: a temperature probe, a pressure switch, a clamp ammeter for measuring an electric current, etc.
Sometimes, we find ourselves in the need of measure “something” for which you can´t find commercial sensors. This can be due to they aren´t common measure needs and there isn´t enough market for these type of sensor or directly, doesn´t exist commercial technical solutions available for different reasons. For example, it could be necessary to measure characteristics such as humidity of solid matter currents, or characteristics only measurable in a quality control laboratory in an indirect way and that needs a high experimentation level.
Also, sometimes, characteristics are required to be measured in very harsh environments due to high temperatures, as it can be melting furnace, or environments with lots of dust that saturate any conventional measure system and it may sometimes be necessary to evaluate a characteristic that is not evenly distributed (for example, quantity of fat in a meat piece, presence of impurities). Other factor to take into account is, that not always possible to be installed a sensor without interferences in the manufacturing process of the material that we want to measure, or the only way is taking a sample to realise an analysis out of the line and obtain a value or characteristic time after, but never in real time.
In these situations, it is necessary to resort to custom-made solutions that we call smart sensors or cognitive sensors. Apart from calling them sound exotic or cool, these are solutions that need to use a series of “conventional” sensors together with software or algorithms, for example, artificial intelligence, that process the measurements returned by these commmercial sensors to try to give as accurate an estimate as possible of the quality we want to measure.
Nowadays we are developing these types of smart sensors for different process industries such as asphalt manufacturing, steel billet and bars or pharmaceutical industry (e.g. pills) in the framework of the European Project CAPRI.
For example, in the manufacture of asphalt, sands of different sizes need to be dried before they are mixed with bitumen. During the continuous drying process of these sands, the finer sand size, called filler, is “released” in the form of dust from larger aggreggates and this dust needs to be industrially vacuumed using what is called a bag filter. Nowadays, the drying and suction of filler is done in a way that ensures that all the filler is extracted. The disadvantage of this process is that it is actually necessary to add additional filler when mixing the dried sands with the bitumen, because the filler improves the cohesion of the mix by filling the gaps between the sand grains. All this drying and complete suction of the filler entails an energy cost that, in order to try to minimise, it would be necessary to have a measure of the filler present in the sand mixture. Today, this measurement is obtained in a punctual way through a granulometric analysis in a laboratory with a sample of the material before drying.
Within CAPRI Project we are working on the complex task of being able to measure the flow of filler sucked in during the drying process. There is no sensor on the market that are guaranteed to measure a large concentration of dust (200,000 mg/m3) in suspension at high temperatures (150-200ºC).
Within the framework of the project, a solution to this problem has been developed, you can consult the laboratory results in the research article recently published in the scientific journal Sensors (“Vibration-Based Smart Sensor for High-Flow Dust Measurement”)
The development of this type of sensors requires various laboratory tests to be carried out under controlled conditions to verify the feasibility of this solution and then, also under laboratory conditions, to carry out calibrated tests to ensure that it is possible to estimate the true flow of filler sucked in during the sand drying process. CAPRI Project has successfully completed the testing of this sensor and others belonging to the manufacture of steel bars and pharmaceutical pills.
The Project in its commitment to the open science initiative promoted by the European Commission has published in its Zenodo channel, different results of these laboratory tests that allow us to corroborate the preliminary success of these sensors pending their validation and testing in the productive areas of the project partners. In the near future we will be able to share the results of the industrial operation of this and other sensors developed in the project.
Co-author
Cristina Vega Martínez. Industrial Engineer. Coordinator at CAPRI H2020 Project
The impact of Artificial Intelligence (AI) is highly recognized as a key driver of the industrial digital revolution together with data and robotics 1 2. To increase AI deployment that is practically and economically feasible in industrial sectors, we need AI applications with more simplified interfaces, without requiring highly skilled workforce but exhibiting longer useful life and requiring less specialized maintenance (e.g. data labelling, training, validation…)
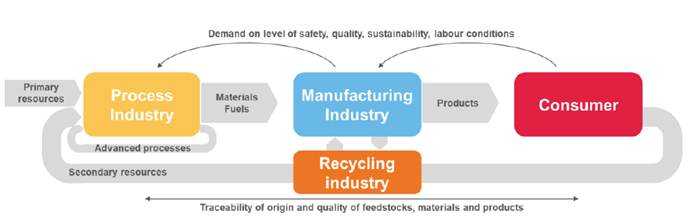
Achieving an effective deployment of trustworthy AI technologies within process indsutries needs a coherent understanding of how these different technologies complement and interact with each other in the context of domain-specific requirements that industrial sectors require3, such as process industries who must leverage the potential of innovation driven by digital transformation, as a key enabler for reaching Green Deal objectives and expected twin green and digital transition needed for a full evolution towards circular economy.
One of the most important challenges for developing innovative solutions in the process industry is the complexity, instability and unpredictability of their processes and impact into their value chains. These solutions usually require: running in harsh conditions, under changes in the values of process parameters, missing a consistent monitoring/measurement of some parameters important for analysing process behaviour and difficult to measure in real time. Sometimes, such parameters are only available through quality control laboratory analysis that are responsible to get the traceability of origin and quality of feedstocks, materials and products.
For AI-based applications, these are even more critical constraints, since AI requires (usually) a considerable amount of high-quality data to ensure the performance of the learning process (in terms of precision and efficiency). Moreover, getting high quality data usually requires an intensive involvement of human experts for curating (or even creating) the data in a time-consuming process. In addition, a supervised learning process requires labelling/classifying the training examples by domain experts, which makes an AI solution not cost-effective.
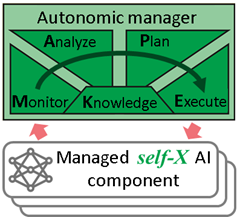
Minimizing (as much as possible) human involvement in the AI creation loop implies some fundamental changes in the organizations of the AI process/life-cycle, especially from the point of view of achieving a more autonomous AI, which leads to the concept of self-X AI4 . To achieve such autonomous behaviour for any kind of application it usually needs to exhibit advanced (self-X) abilities like the ones proposed for the autonomic computing (AC)5:
Self-X Autonomic Computing abilities
Self-Configuration (for easier integration of new systems for change adaptation)
Self-Optimization (automatic resource control for optimal functioning)
Self-Healing (detection, diagnose and repair for error correction)
Self-Protection (identification and protection from attacks in a proactive manner)
AutonomicComputing paradigm can support many AI tasks with an appropiate management, as already reported in the scientific community 6 7 . In AI acts as the intelligent processing system and the autonomic manager (continuously executes a loop of monitoring-analyzing-planning-executing based on the knowledge (MAPE-K) of the AI system under control for developing a self-improving AI application.
Indeed, such new (self-X) AI applications will be, to some extent, self-managed to improve their own performance incrementally5. This will be realized by an adaptation loop, which enables “learning by doing” using MAPE-K model and self-X abilities as proposed by autonomic computing. The improvement process should be based on continuous self-Optimization ability (e.g. hyper-parameter tuning in Machine Learning). Moreover, in the case of having some problems in the functioning of an AI component, the autonomic manager should activate self-Configuration (e.g. choice of AI method), self-Healing (e.g. detecting model drify) and self-Protection abilities (e.g. generating artificial data to improve trained models) as needed, based on knowledge from AI system.
In just a few weeks, CARTIF will start a project with the help of AI experts and leading companies of various process industry sectors across Europe to tackle these challenges and close the gap between the AI and automation by proposing a novel approach for a continuous update of AI applications with minimal human expert intervention, based on an AI data pipeline, which exposes autonomic computing (self-X) abilities, so called self-X AI. The main idea is to enable the continuous update of AI applications by integrating industrial data from physical world with reduced human intervention.
We’ll let you know in future posts about our progress with this new generation of self-improving AI applications for the industry.