Imagine if every product that reaches your hands could explain its story: where it comes from, what materials it was made with, what processes it went through, how its quality was guaranteed and under what conditions it was transported to its destination.
We live in an era in where information is everything. However, in the industrial world we still let valuable data get lost in siloed systems and time-sensistive decisiones. What if we could make that data visible, useful and connected?
Today, thanks to technologies such as Industry 4.0 and real-time capture systems, production plants generate more information than ever before. But having dat is not enough. The key is structuring, interpreting and connecting it. Turning disparate data into useful knowledge is the first step toward truly intelligent digital labeling.
This is precisely what the European projectbi0space is seeking: to develop a digital labeling system for bio-based products that allows each batch to be traced from origin to delivery. This system not only collect technical information ont raw materials, processes and quality controls, but will also include logisitcs data, transportation conditions and environmental KPIs.
Why it is necessary the digital labelling?
In today’s industrial processes, much of the key information about a product’s manufacturing is scattered across different platforms or unstructured. This makes complete traceability of what happens in the plant difficult and, consequently, complicates operational decision-making, continuous improvement, and the justification of sustainability and quality standards. In the context of bio-based production, where materials can vary depending on the supplier, harvest, or process, having control over each stage of the product’s lifecycle becomes especially important. Hence the need to establish a system that allows all this information to be collected and accessed in a unified and accessible manner.
What type of information will be collected?
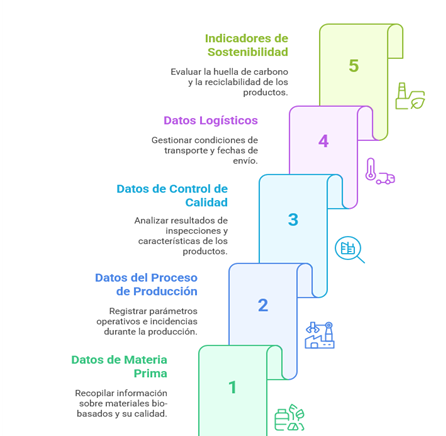
The digital labeling system being designed at biOSpace includes five essential blocks of information:
All this data is linked by a unique digital identifier that accompanies the product throughout its entire journey, from entry into the factory to exit. This label is progressively completed, adding information as the product goes through different stages of the process: raw material reception, processing, quality control, packaging, transportation, etc.
This modular identifier structure allows for precise tracing of the product´s journey and condition at each stage, ensuring all relevant information is connected in a clear and structured manner.
What can be reach thanks to the integral traceability?
The value of this information lies not only in its storage, but also in its practical use, tailored to each need. Therefore one of the goals is to enable the system to be accessed from internal dashboards that help plant staff make decisions in real-time, and that at the same time to be integrated into broader digital environments, such as management systems or digital twin platforms.
Furthermore, the same digital label can offer different levels of information depending on the profile of the user consulting it. An operator can view technical data on the process or quality controls, while a sutainability manager can acces environmental KPIs, and an end consumer can view an accesible summary of the product´s origin, characteristics, and traceability.
This detailed traceability will also contribute to what is now becoming known as the digital product passport, a tool that is gaining importance within the framework of European policies toward a more transparent and circular economy.
“What we do with our data today sets the course for what we will do with our products tomorrow”
Although this solution is still in the design phase, it´s based on a simple but important question: what are we doing with all the information already generated in our factories?
In several cases, data exists, but it´s not connected, shared, or simply not used. This project seeks precisely that: to make sense of it, organize it, and make it availabke to those who need it, from the operator who manages a batch to the strategic decision-maker or the persona who, at the end of the chain, consumes the product.
It´s not about incorporating technology as a trend, but rather about using it with criteria. It´s about building tools that allow us to better understand what we produce, how we do it and what impact it has, at a time when traceability, sustainability and transparency are no longer options, but rather conditions for continued progress.
In the world of software development, interoperability is the ability of different devices, systems, and applications to work together in a coordinated manner, much like musicians in the Vienna Symphony Orchestra, regardless of their origin or technology. This concept is essential in digital transformation, where systems, such as a robotic application, must integrate with multiple platforms, including robotic control systems, artificial intelligence solutions, and industrial IT management platforms like ERP (Enterprise Resource Planning) or MES (Manufacturing Execution System).
The primary goal is to facilitate real-time data exchange for smarter decision-making. Interoperability plays a crucial role in robotics by enabling seamless integration between heterogeneous industrial production systems and digital platforms.
Benefits of interoperability
Adopting interoperability technologies in robotic application development brings multiple advantages, including:
Intelligent asset management and remote monitoring of robots and machine tools, allowing centralized, real-time control of distributed systems.
Optimized decision-making: With real-time data availability, organizations can enhance their responsiveness to unexpected events and optimize workflows.
Scalability and modularity: Enabling the integration of new technologies, sensors, and robots without the need for complete system redesigns, supporting adaptability to future industrial needs.
Cost and downtime reduction in production lines through the integration of heterogeneous systems, minimizing setup times and allowing quick reconfiguration and process flexibility in dynamic environments.
Predictive maintenance and resource optimization: Using AI-based models to anticipate failures, optimize spare part usage, and extend equipment lifespan without compromising productivity.
FIWARE as an interoperability enabler
For robotic systems to integrate efficiently, they must be compatible with standardized platforms that enable intelligent data management and communication. FIWARE, which we work with in the ARISE project, is a set of technologies, architectures, and standards that accelerate the development and deployment of open-source solutions. As a leading technology in the European Union, FIWARE primarily contributes to the creation of interoperable tools and services for real-time data management and analysis, ensuring persistence, flexibility, and scalability, thereby enabling the development of customized applications without excessive costs.
Another key value proposition is its multi-sector nature. FIWARE’s standardized reference components and architectures allow any solution designed for a specific sector—such as manufacturing, logistics, or services—to be inherently interoperable with other verticals, including energy management, mobility, or emerging data spaces.
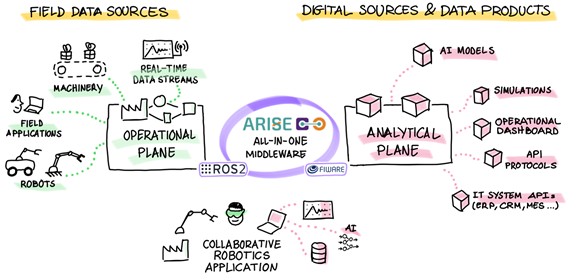
In ARISE, we develop robotic applications for human-robot interaction by integrating our ARISE middleware (a middleware solution that incorporates Vulcanexus, ROS2, FIWARE, and ROS4HRI) into four experimental environments. These environments explore connected robotic solutions with FIWARE in an Industry 5.0 scenario. One of these environments is in CARTIF, a laboratory for testing and validating technology in controlled environments (TRL 4-5). Figure 1 below shows this experimental setup:
Fig 1. CARTIF testing environment
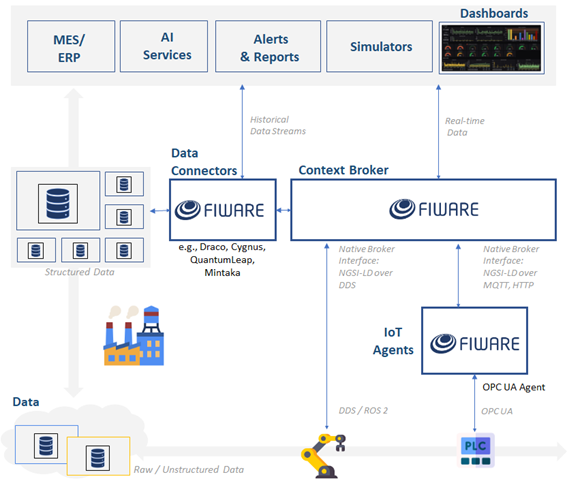
FIWARE plays a fundamental role in providing tools that enable interoperability between heterogeneous systems, ensuring seamless integration of real-time data and IoT devices, as well as dynamic data management from the operational level, allowing communication between different systems, devices, and platforms toward the analytical level. This ensures deep integration with enterprise IT/OT infrastructures (see Figure 2):
Fig 2. ARISE middleware ecosystem
Designing a FIWARE architecture and key components
The design of a FIWARE architecture follows a modular approach, where components are integrated according to application needs. The architecture is built around its core component, the Context Broker, which manages real-time data flows. To implement FIWARE effectively, it is recommended to follow these steps:
Define the use case: identify the application’s objectives and requirements.
Select the appropriate architecture: include the Context Broker, IoT Agents, and other components as needed, converting heterogeneous protocols into FIWARE-compatible data. For example, the OPC-UA IoT Agent enables real-time management of data collected in industrial environments, facilitating interoperability with other systems.
Integrate devices and systems: connect sensors, robots, or other systems via OPC-UA, MQTT, or other protocols.
Implement security and access control: use Keyrock and PEP Proxy to ensure data protection, authentication, and access control.
Store and analyze data: utilize Cygnus, Draco, or QuantumLeap for valuable insights, historical data storage, persistence, and Big Data analysis.
Deploy in the cloud or local environments: consider FIWARE Lab or private infrastructure for hosting services.
Monitoring and optimization: evaluate system performance and improve integration with platforms like AI-on-Demand or Digital Robotics. Wirecloud enables the creation of custom visual dashboards, facilitating easy integration with applications like Grafana and Apache Superset.
Fig 3. FIWARE architecture modules and application example
At CARTIF, we continue to invest in these technologies to build a future where system and platform collaboration is the key to success. Recently, we joined the FIWARE iHubs network under the name CARTIFactory. As an official iHub, it will not only promote FIWARE adoption but also serve as a reference center with its experimentation lab, fostering interoperability in robotic applications within our community and industrial ecosystem.
Interoperability is not just a technical requirement but a fundamental pillar for the success of digital transformation in industry. Technologies like FIWARE enable the connection of systems, process optimization, and the development of a flexible and scalable ecosystem. Thanks to this capability, companies can integrate artificial intelligence, robotics, and advanced automation seamlessly.
Co-authors
Aníbal Reñones. Head of the Industry 4.0 Area, Industrial and Digital Systems Division
Francisco Meléndez. Robotics Expert and FIWARE Evangelist, Technical Coordinator of the ARISE Project (FIWARE Foundation)
Artificial intelligence (AI) is no longer the stuff of futuristic fantasy; it has become a tangible part of our everyday lives. From personalised recommendations on streaming platforms to optimising logistics processes in a factory, AI is everywhere. What’s interesting is that it’s not just making our lives easier, it’s also transforming industry.
In the HUMAIN project, where we are working with companies such as BAMA and CENTUM, we are taking AI to the next level. Imagine a factory that can anticipate problems before they happen, thanks to data-driven predictive systems. Or robots working alongside humans to efficiently pack and palletise products, even if the boxes are of different sizes. It’s like switching from a manual to an automatic car!
But this is not science fiction. We are researching and developing artificial intelligence algorithms that turn vast amounts of data into intelligent decisions, computer vision systems that see beyond what the human eye can see, and machine learning-based predictive maintenance solutions that save time and money. AI acts as a strategic brain that optimises every aspect of the process, from production to logistics. The result? More sustainable operations, less waste and smarter factories.
These kinds of projects don’t just benefit large companies. They also have a direct impact on our lives. Think about it: every time you buy something online and it arrives on your doorstep in record time, there is probably an AI system behind it that has optimised every step of the process. From packaging to delivery.
In the HUMAIN project consortium, we are excited to be part of this revolution. It’s not just about making machines work faster, it’s about integrating disruptive technologies that put people at the centre of the process. After all, AI is a tool: it’s how we use it to improve our everyday lives that matters.
Are we ready to embrace this industrial revolution? The answer lies in every click, every purchase, and every robot working hand in hand with us.
Artificial intelligence (AI) is contributing to the transformation of a large number of sectors, from suggesting a song to analyzing our health status via a watch, along with manufacturing industry. One hindrance on this transformation relates to the overall complexity of AI systems, which often poses challenges in terms of transparency and comprehensions of the results delivered. In this context, the AI’s explanatory capability (or “explainability”) is referred as the ability to make their decisions and actions understandable to users – which is known as eXplainable AI (XAI); this is something crucial to generate trust and ensure a responsible adoption of these technologies.
Explainable AI (XAI); the ability to make their decisions and actions understandable to users
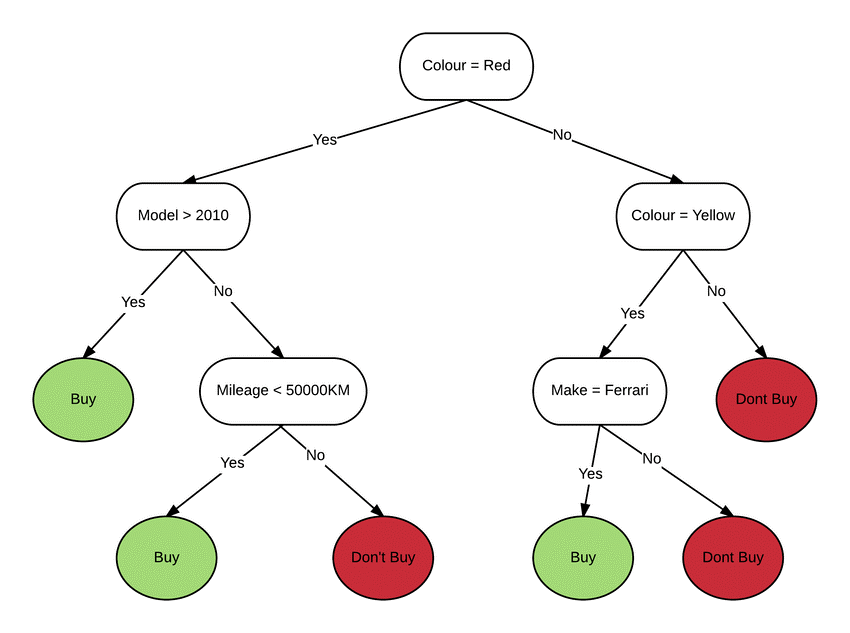
A wide range of technological solutions are currently being investigated in order to improve the explainability of AI algorithms. One of the main strategies includes the creation of intrinsically explainable models (ante hoc explanations). This type of models, such as decision trees and association rules, are designed to be transparent and comprehensible by their own nature. Their logical structure allows users to seamlessly follow the reasoning behind the AI-based decisions. Tools for visualization of AI explanations are key, since they represent graphically the decision-making process performed by the model, thus facilitating user comprehension. These tools might take different forms, such as dedicated dashboards, augmented reality glasses, or natural language explanations (as speech or as text).
Intrinsically explainable system: decision tree. The intermediary nodes are conditions that are progressively verified until reaching the final result
Natural Language explanations for a recommender system of new routes for exercising. Extracted from Xu et al. (2023). XAIR: framework of XAI in augmented reality.
Another commonly used family of explanation techniques is called post hocmethods: these consist in, once the AI model has been created and trained, a posteriori processing and analyzing this resulting model to provide explanations of the results. For example, some of these techniques evaluate how much is contributed by each input variable in the final result of the system (sensibility analysis). Among post hoc explainability techniques, SHAP (Shapley Additive exPlanations), a method based on cooperative game theory, allows to extract coefficients that determine the importance of each input variable on the final result of an AI algorithm.
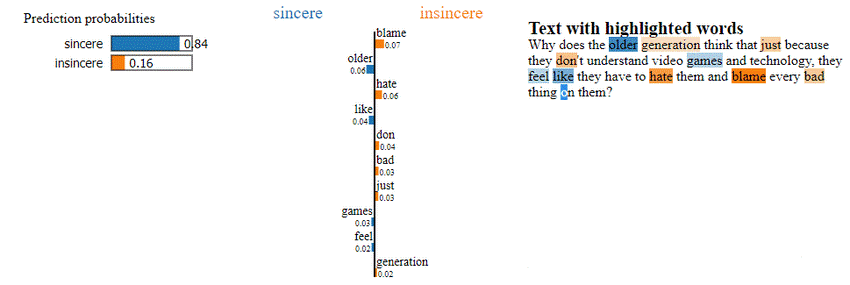
Other XAI techniques include decomposition, which divides the AI model into simpler and more easily explainable components, and knowledge distillation into surrogate models, which approximate the function of the original system while being more easily comprehensible. On the other hand, the so-called “local explanations” consist in methods that explain individual examples (input-output), not the entire AI model. An example are the explanations provided by tools such as LIME (Local Interpretable Model-agnostic Explanations). As an illustration of LIME, the example in the following figure shows a specific inference in text classification task, in which a text is classified as “sincere” (with 84% of likelihood), and the most relevant words for that decision are highlighted, as an explanation of this individual classification [Linardatos et al. (2020)].
An additional approach for XAI relates to the integration of input by users in the process of AI model construction, which is known in general as “Human-in-the-Loop” (HITL). This approach allows users to interact (e.g. by labelling new data) and to supervise the AI algorithm building process, adjusting its decisions in real time and thus improving the overall system transparency.
At CARTIF, we are actively working in different projects related with AI, such as s-X-AIPI to help advance in the explainability of AI systems used in industrial applications. A significant example in our work are dashboards (visualization or control panels) designed for the supervision and analysis of the performance of fabrication processes studied in the project. These dashboards allow plant operators to visualize and understand in real time the actual status of the industrial process.
Predictive and anomaly detection models have been created in the context of asphalt industrial processes which not only anticipate future values, but also detect unusual situations in the asphalt process and explain the factors that have an influence on these predictions and detections. Thus, this helps operators make adequate informed decisions and better understand the results generated by the AI systems and how to take proper actions.
Explainability in AI methods is essential for the safe and effective AI adoption in all types of sectors: industry, retail, logistics, pharma, construction… In CARTIF, we are committed with the development of technologies to create AI-based applications that do not only improve processes and services, but also are transparent and comprehensible for users; in short, that are explainable.
Co-author
Iñaki Fernández.PhD in Artificial Intelligence. Researcher at the Health and Wellbeing Area of CARTIF.
Imagine finding out that the pilot of your next flight will be using Apple Vision Pro while in command of the plane. Would you feel comfortable boarding that plane? If your answer is no, you might think the pilot is reckless and that your life is at risk. On the other hand, if your answer is yes, you probably know the potential of using this device in such a situation.
Recently, the world was caught up in this debate when a pilot in the United States was recorded using Apple Vision Pro during a flight1. The pilot claimed to have improved productivity with this device. However, he faced significant criticism and had to apologize after deleting the video.
Why did this case cause so much outrage? In reality, many sectors use these types of devices daily, such as surgery, architecture, engineering, and training. The reason is simple: we are progressing. Although humans are skeptical of new technologies, we recognize that they can improve our lives. A clear example is e-commerce; when it started, many people thought it was dangerous. Now, Amazon is the fifth most valuable company in the United States, and in Spain, 39% of the population shops online at least once a month2.
It’s likely that over time, this feeling will also dissipate in the case of extended reality. This term, which encompasses virtual reality, augmented reality, and mixed reality, can be confusing for many. Each technology serves a specific purpose based on the level of immersion: virtual reality creates entirely digital environments, augmented reality overlays digital elements onto the physical reality, and mixed reality combines both to provide spatial awareness to digital elements. This concept is best understood when looking at the following image.
Differences between virtual reality, augmented reality and mixed reality. Source: Avi Barel3
In the image, you can see how in mixed reality, an object like a rubber duck can recognize its surroundings and position itself behind a table instead of going through it as it would in augmented reality. This is the magic of mixed reality!
Although Apple Vision Pro has incredible features, similar devices have existed for a long time, something that CARTIF is well aware of. That’s why in the Industrial and Digital Systems Division, we have long been using the Microsoft HoloLens 2 mixed reality device for various purposes.
In the Baterurgia project, we are using this technology to automate the disassembly of electric car batteries and promote human-robot interaction. To achieve this, we rely on robotics and computer vision to detect screws present in a battery. Through the lenses of the Microsoft HoloLens 2, the operator sees holograms indicating the position of the screws in space. The operator can select a screw with a finger or gaze and issue instructions to the robot via voice commands. The system provides feedback on the progress of the activity, allowing the operator to perform other tasks simultaneously.
Secuence for picking up a screw (Recorded with Microsoft HoloLens 2)
Display of the camera image showing detected screws.
Identification and marking of the screws.
The operator selects a screw.
The robot picks up the selected screw.
As you have seen, mixed reality is gaining popularity and being applied in more sectors. The high cost of products like Apple Vision Pro and Microsoft HoloLens 2, which are around $3500, is a significant limitation. However, new more affordable devices like Meta Quest 3, which costs around $500, are making this technology more accessible for companies and users. Along these lines, it is projected that the global sales of extended reality devices will increase to 105 million by 20254 .
If this post has intrigued you and you wish to explore more about extended reality and its impact, I’d be happy to share more information with you!
When a Project finalises, it is the time to recapitulate, time to collect all the information and the experience gained along. Along the three years and a half working in CAPRI project there has been a lot of time to do things, to obtain very good results or to feel bad because many times nothing seems to works well the first time.
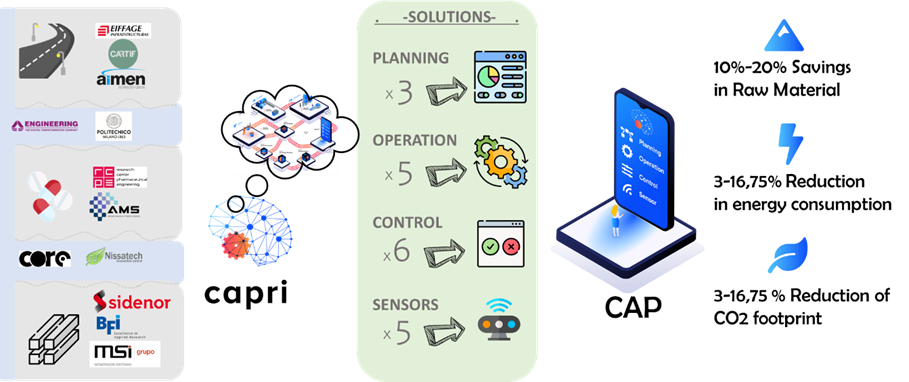
CAPRI project, has finalised in September 2023 and has achieved its main objectives defined during the beginning which were driven by the need of help in the digital transformation of the European process industry by investigating, developing and testing a cognitive automation platform. CAP, that integrates 19 different cognitive solutions defined in each one of the three project’s pilot plants. This platform has been designed to achieve the ultimate goal to obtain reductions of use of raw materials, energy consumption and CO2 footprint. With the finalization of the project, it can be shown that the reductions have been achieved thanks to the very close collaboration of the twelve partners involved, from seven different countries. The cognitive platform and solutions were deployed in three important sectors of the process industry: Asphalt manufacturing, billets and bars of Steel production and the production of tablets in the pharma industry.
For example, the asphalt pilot plant from EIFFAGEInfraestructuras, the cognitive solutions were related with the four automation levels, from sensors to planning, covering all of them.
The final prototype demonstrated under actual operation of the asphalt plant included very different technologies such as computer vision, vibration analysis, neural networks or mathematical models for parametrization of the existing data to predict the key performance indicators (specific energy consumption per tonne of asphalt mix or the final amount of raw materials used).
The cognitive solutions developed, like the cognitive control of the dryer drum or the new sensors, assures the quality of products and production in real time, reducing the used energy and raw materials. Before the project, the control of the materials used was based on estimations and now, with the mathematical model for mass balance and new sensors, the plant operators can receive an information in real time they didn’t have before.
The expected results of each Cognitive Solutions were defined during the first stages of the project to verify the improvements of each one during the validation period of the project.
CAPRI Project offers innovative solutions that have the potential to transform industries and drive progress. It highlights the project’s focus on unlocking new possibilities and empowering various sectors with cutting-edge advancements thanks to the generated key exploitable results.
Respect these results, inside the Asphalt use case, it has been included as exploitable results 3 solutions: a sensor to measure the dust aspirated online inside a pipe, the amount of bitumen present in recycled asphalt, and a predictive maintenance system of plant’s baghouse based on cognitive sensors and expert knowledge. The steel use case generated 2 exploitable results: a cognitive steel solidification sensor for continuous casting processes and a steel Product tracking. The pharma use case has 2 exploitable results: a cognitive sensor for granule quality and a quality attributes sensor.
The project generated also some transversal key exploitable results useful for any kind of industry: the technical architecture of the cognitive automation platform or CAP, and another one related to the open data generated, showing CAPRI project’s commitment with the open science the FAIR principles through the generation of more than 50 assets shared in open platforms, like Zenodo.
The main objectives of the proposal were the reduction of use of raw materials, energy and CO2 footprint. We can say with pride that we achieved those objectives as you can see in the summary table.
KPI
After CAPRI
5% – 20% Savings in Raw Material
10-20%
5% overall reduction in energy consumption
3-16.75%
5% reduction of CO2 foot print
3-16.75%
As an engineer, when a project finalises on time, and with these very good results, when your project has contributed to improve the industry, without damaging our environment, you feel better and all the sacrifices, extra hours and bad reviews was worth it.