Elicitation (from the latin elicitus “induced” and elicere “to catch”) is a term associated with psychology that refers to the fluid transfer of information from one human being to another by means of language.
The knowledge elicitation applied to industry is a process by which valuable information and knowledge is collected and recorded from experts or people with experience in a particular area in the organization. Is a technique used to identify, extract and document the tacit knowledge (implicit) that is in the mind of the individuals or in the organizational processes. It is a way to collect and record the existing knowledge not available in formal documentation and is used in different fields such as knowledge- management, engineering, business, among others. The knowledge elicitation could be use inside the engineering field to optimize industrial processes, create expert systems, for apps based in AI, etc.
For example, if it were technologically possible to access the minds of workers as in the fictional series Severance, where a sinister biotech corporation, Lumon Industries, uses a medical procedure to separate work and non-work memories, this knowledge could be recorded and available for use, but it is also clear that this premise would raise significant ethical and legal concerns at this point in history, we do not know in the near future.
The knowledge elicitation is important for different reasons. In first place, allows organizations to document the existent knowledge of their employees and experts in an specific area.This can help to avoid re-invention of the wheel and improve efficiency in decision-making. Secondly, knowledge elicitation can also help to identify gaps in an organisation’s knowledge, enabling them to take action in advance. Thirdly, this elicitation process can help foster collaboration and knowledge sharing among an organisation’s employees.
The aim of elicitation is to obtain accurate and relevant information to aid decision-making, improve efficiency and support training and development. This information is used to develop optimal rules for expert performance that serve as the main input for the controls that can be programmed into a production process.
Knowledge elicitation is important for several reasons. Firstly (1), it allows organisations to document the existing knowledge of experts in a specific area. This can help to avoid re-invention of the wheel and improve efficiency in decision-making. Secondly (2), knowledge elicitation can also help to identify gaps in an organisation’s knowledge, allowing organisations to take action in advance. Thirdly (3), this elicitation process can help foster collaboration and knowledge sharing among an organisation’s employees.
The methodology for knowledge elicitation requires a series of steps to be followed:
Requirements analysis: identifying the approach to knowledge-based systems.
Conceptual modelling: creating a base of terminology used, defining interrelationships and constraints.
Construction of a knowledge base: rules, facts, cases or constraints.
Operation and validation: Operating using automated reasoning mechanisms.
Return to requirements analysis if necessary or continue with the process.
Enhancement and maintenance: Expanding knowledge as the system evolves, repeat throughout the life of the system.
Subsequently, it is necessary to analyse the knowledge collected, to determine which information is relevant and which is not, by distinguishing and separating the parts of a whole until its principles or elements are known, the result of which is high quality knowledge. The verification or detection of defects of the requirements previously analysed, normally by means of techniques such as formal reviews, checklists, etc.
The following elements are necessary for the correct development of the tendering process:
Experts
The different experts on the procces can have different point of views of a same theme, due to their experience, knowledge and even more subjective aspects such as mentality, way of focus difficulties, challenges, etc. Should be considered experts specialists in different stages, different infrastructures, equipment, products,etc.
The barriers that can appear in this type of exchange of information is that often contain complex ideas and associations, hard to comunicate in an easy way, with detail and organization, the use of a same language, such as concepts or specific vocabulary.
The knowledge elicitation has an objective search, research and help users or experts in the productive process in this case, to document their own needs by an on-site or online interview, group meetings, in situ studies, etc.
Interviews
To acquire expert knowledge the best technique is carrying out a number of personal interviews, some of the disadvantages are; distance, time and people involved on this process, the paper or online questionnaires can be viable option that saves time and costs and it is made easier for all sections to be present, enabling the comparative and evaluation of the results.
The characteristics for a good questionnaire design: define the relevant information, good structuring with different sections organized by themes, organizes points from general to more detailed in each section, focusing on the idea of those section,it is avoid the introduction of tendencies, misunderstandings or mistakes, to realize the design with an expert of the domain to ensure that points are enough understandable to facilitate the answer.
Results
The expected results are the actions to make by the operators when parameters deviations are produced, those answers and information collected are transform intop optimal needed rules to program authomatic controls about the process, and whre this rules are the main element. The obtention of rules is not an easy task, an iterative and heuristic process in several phases is recommended. For the validation it is necessary the comparative of the collected information at the databases with the answers of the operator to verify the actions when parameters deviations of the desired values are produced.
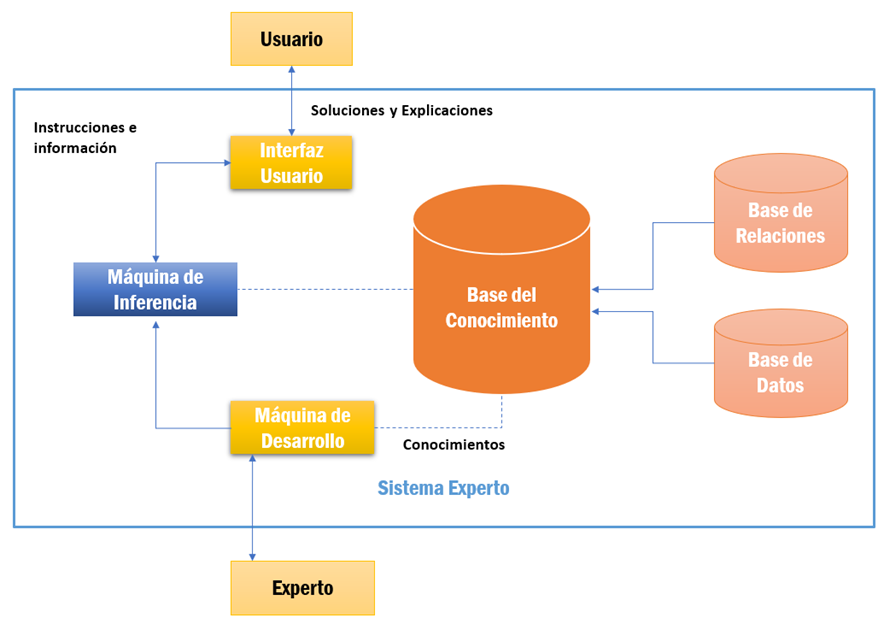
This optimal rules or also denominated if-then rules are part of the knowledge base, in particular of the relations base, that is the part of an expert system that contains the knowledge about the domain. In first place, the knowledge of the expert is obtained and it is codified in the relations base.
Finally, it is when fuzzy logic can be used for the design and implementation of an expert system, which is the logic that uses expressions that are neither totally true nor false, allowing to deal with imprecise information such as average height or low temperature, in terms of so-called “fuzzy” sets that are combined in rules to define actions: e.g. “if the temperature is high then cool down a lot”. This type of logic is necessary if one wants to better approximate the way of thinking of an expert, whose reasoning is not based on true and false values typical of classical logic, but requires extensive handling of ambiguities and uncertainties typical of human psychology.
Currently in CARTIF the expert elicitation knowledge of the plant operators are been used at the INTELIFER project, which main objective is the optimization of the process and of the products of a manufacturing line of NPK granulated fertilisers with support of the artificial intelligence.
The operation of these type of granulated fertilisers plants is controlled manualli and heuristically by expert operators, but that, despite of its skills and habilities, they can not avoid the high rates of recycle, frequent inestabilities and non-desired stops, as well as the limite quality of the products. Due to the extremely complex nature of the granulated process, which includes multistages, multiproduct, multivariables, is not lineal, coupled, stochastic. So that the situation before exposed has meant the scientific base for the defiition of the present project, being necessary the development of R&D activities in which, by the application of the artificial intelligence philosophy joint with a higher degree of sensorization and digitalization, is achieved to optimize this type of manufacturing processes.
The common denominator of artificial intelligence is the need of available, good qualilty and real data to advance in the different procedures needed to create and train the models. Practical research in AI often lacks available and reliable datasets so the practitioners can try different AI algortihms to solve different problems.
In some industrial research fields like predictive maintenance is particularly challenging in this aspect as many researchers do not have access to full-size industrial equipment or there are not available datasets representing a rich information content in different evolutions of faults that can happen to an asset or machine. In addition to that, the available datasets are clearly unbalances as the norm for machines is that they operate properly and only few examples of faults appear during their lifetime.
It´s very important from the AI research point of view the availability of reliable and interesting data sources that can provide a variety of examples to test different signal processing algorithms and introduce students and researchers into practical application such as signal processing, classification or prediction.
The ideal situation for researchers and developers of artificial intelligence solutions is that everyone, to a certain extent, shares data. But sharing data cannot be seen only as a way to help other people, sharing research data can bring many advantages to the data donor:
It´s part of good data practice and open science as it is encouraged to make data accesible together with the scientific papers generated.
Cut down on academic fraud and prevent publications of studies based on fake data.
Validate results. Anyone can make a mistake, if we share the data we used, other researchers could replicate our work and detect any potential error in our work.
More sicentific breakthroughs. This is especially true in social and health science where data sharing would enable for example more studies in human brain as Alzheimer´s Disease and many others.
A citation advantage. Studies that make data available in a public repository are more likely to receive more citations than similar studies for which the data is not made available.
Best teaching tools based on real cases.
At Europe level the European Commission has launched the Open Research Europe, a scientific publishing service, for Horizon 2020 and Horizon Europe beneficiaries with a service to publish their results in full compliance with commission open access policies. The service provides an easy, high quality peer-reviewed venue to publish their results in open access, at no cost to them. Other interesting service part of this open research initiative is Zenodo, an open repository to upload your research results. In addition to the open research publishing guidelines, data guidelines are also available which adheres the F.A.I.R principles too and refers a number of trusted repositories like Zenodo, that we are obliged to use based on the European project rules.
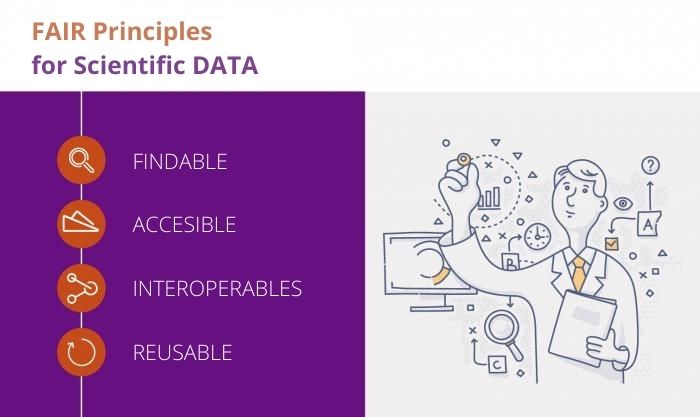
The FAIR guiding principles for publishing data mean that the data and its meta-data that defines it must be:
Findable: (meta)data are assigned a globally unique and persistent identifier.
Accessible: (meta)data are retrievable by their identifier using a standardized communications protocol.
Interoperable: (meta)data use a formal, accessible, shared, and broadly applicable language for knowledge representation.
Reusable: meta(data) are richly described with a plurality of accurate and relevant attributes.
Besides, from the governmental point of view European Commission, both European Data Strategy and Data Governance policy are powerful initiatives focus on the implementation of European data spaces, among which the Commission proposes the creation of a specific European industrial (manufacturing) data space to take advantages of the strong European industrial base and improve their competitiveness.
As researchers in CARTIF, we are committed to promote such openness with our research projects. For example, for CAPRI project it has been recently created its own Zenodo channel repository, where we periodically upload project results of the advanced solutions we are developing for the process industry such as cognitive sensors or cognitive control algorithms. You can go to the repository and inspect more than 40 datsasets, sourcecode or videos we already have uploaded.
Machine vision is one of the enablers of Industry 4.0 with increased integration in production lines, especially in the quality control of products and processes. In recent years, a real revolution is taking place in this field with the integration of Artificial Intelligence in image processing, with a potential yet to be discovered. Despite the limitations of Artificial Intelligence in terms of reliability, results are being obtained in industry that were previously unthinkable using traditional machine vision.
The purpose of this post is not to talk about the possibilities of Artificial Intelligence, as there are many blogs that deal with this task, the purpose is to highlight the potential of traditional machine vision when you have experience and develop good ideas.
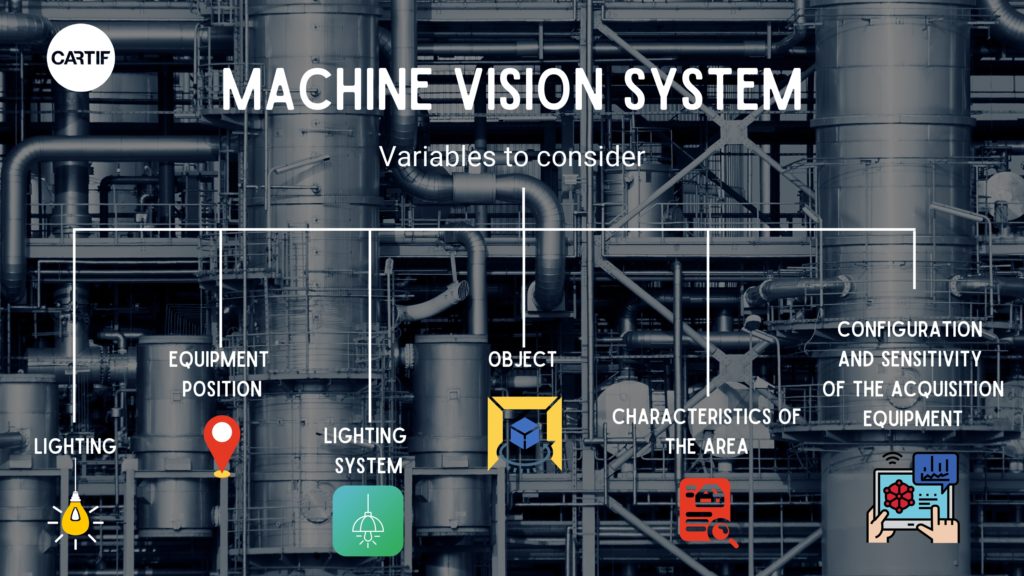
Machine vision is not just a set of algorithms that are applied directly to images obtained by high-performance cameras. When we develop a machine vision system, we do so to detect a variety of defects or product characteristics. Our task is to select the most appropriate technology and generate the optimal conditions in the scene in order to extract the required information from the physical world from the captured images. There are many variables to consider in this task: the characteristics of the lighting used in the scene; the relative position between the acquisition equipment, the lighting system and the object to be analysed; the characteristics of the inspection area; the configuration and sensitivity of the acquisition systems, etc.
As a representative anecdote of the importance of experience, I would like to highlight a case that was given to us in an automative components factory.
The company had installed a high-performance commercial vision system whose objective was to identify various parts based on colour. After several failures, we were asked to help configure the equipment, but instead of acting on these devices, we worked on changing the lighting conditions of the scene and simply turned the spotlights around and placed panels to obtain diffuse lighting instead of direct lighting. This solved the problem and the vision reached the level of reliability required by the client.
In this post, I would like to highlight an important case of success in the automative industry that has had a relevant impact on its production process, this is the SIVAM5 vision system developed by CARTIF and integrated in cold drawing lines of laminated sheet metal.
As we all know, the surface quality of the vehicle´s exterior is key for users, which is why companies in the automotive sector have to make a significant effort to detect and correct the presence of defects in the bodywork of their vehicles. Most of these defects occur at the stamping stage, but considering the inconsistency of the colour of the sheet metal and the generation of diffuse reflections, in some cases these defects go unnoticed to the body assembly stage and then to the painting stage, after which they become noticeable. This means that a small defect not detected in time translates into a large cost for the production of the vehicle.
To detect these defects at an early stage, we have developed an innovative machine vision system to detect the micro-cracks and pores that are generated in the cold stamping process of rolled sheet metal. This is a clear example of a robust solution based on a simple idea, “the passage of light through the pores of the sheet metal”, but where a great technological effort has been made to implement the idea in the production line. To this end, various optical technologies have been combined with the development of complex mechanical systems, resulting in a high -performance technological solution, capable of carrying out an exhaustive inspection of the critical points of the sheets in 100% of the production and without penalising the short cadence times that characterise press lines.
Thanks to its excellent resistance to vibrations and impacts, its great adptability for the integration of new references and its reliability in the detection of defects, a robust, flexible and reliable solution has been obtained. Based on a simple idea, a robust solution has been implemented in the production process of large companies in the automotive sector, such as Renault and Gestamp, where it has been operating without updates for more than 20 years, working day and night.
Researchers are increasingly confronted with situations of “digitalise” something that has not been digitalised before, temperatures, pressures, energy consumes,etc. for these cases we look for measure systems or a sensor in a commercial catalogue: a temperature probe, a pressure switch, a clamp ammeter for measuring an electric current, etc.
Sometimes, we find ourselves in the need of measure “something” for which you can´t find commercial sensors. This can be due to they aren´t common measure needs and there isn´t enough market for these type of sensor or directly, doesn´t exist commercial technical solutions available for different reasons. For example, it could be necessary to measure characteristics such as humidity of solid matter currents, or characteristics only measurable in a quality control laboratory in an indirect way and that needs a high experimentation level.
Also, sometimes, characteristics are required to be measured in very harsh environments due to high temperatures, as it can be melting furnace, or environments with lots of dust that saturate any conventional measure system and it may sometimes be necessary to evaluate a characteristic that is not evenly distributed (for example, quantity of fat in a meat piece, presence of impurities). Other factor to take into account is, that not always possible to be installed a sensor without interferences in the manufacturing process of the material that we want to measure, or the only way is taking a sample to realise an analysis out of the line and obtain a value or characteristic time after, but never in real time.
In these situations, it is necessary to resort to custom-made solutions that we call smart sensors or cognitive sensors. Apart from calling them sound exotic or cool, these are solutions that need to use a series of “conventional” sensors together with software or algorithms, for example, artificial intelligence, that process the measurements returned by these commmercial sensors to try to give as accurate an estimate as possible of the quality we want to measure.
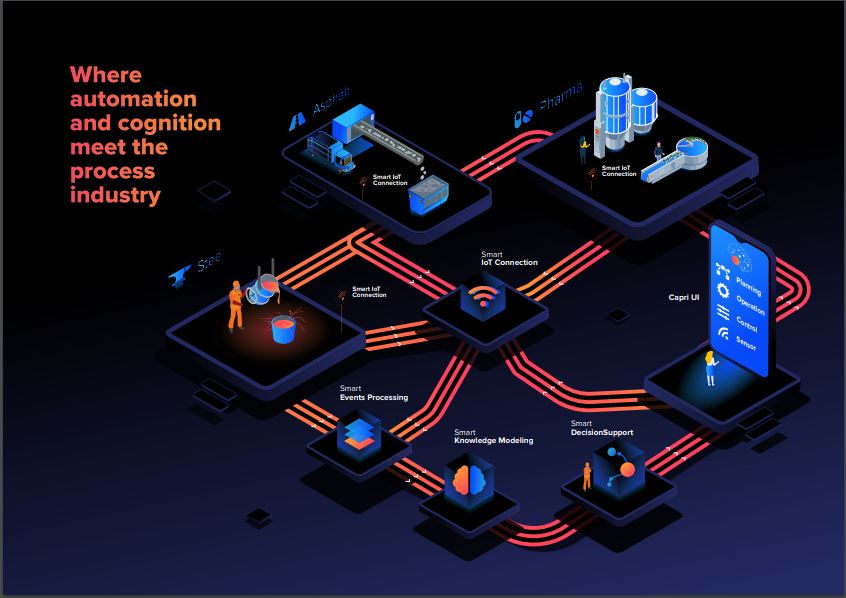
Nowadays we are developing these types of smart sensors for different process industries such as asphalt manufacturing, steel billet and bars or pharmaceutical industry (e.g. pills) in the framework of the European Project CAPRI.
For example, in the manufacture of asphalt, sands of different sizes need to be dried before they are mixed with bitumen. During the continuous drying process of these sands, the finer sand size, called filler, is “released” in the form of dust from larger aggreggates and this dust needs to be industrially vacuumed using what is called a bag filter. Nowadays, the drying and suction of filler is done in a way that ensures that all the filler is extracted. The disadvantage of this process is that it is actually necessary to add additional filler when mixing the dried sands with the bitumen, because the filler improves the cohesion of the mix by filling the gaps between the sand grains. All this drying and complete suction of the filler entails an energy cost that, in order to try to minimise, it would be necessary to have a measure of the filler present in the sand mixture. Today, this measurement is obtained in a punctual way through a granulometric analysis in a laboratory with a sample of the material before drying.
Within CAPRI Project we are working on the complex task of being able to measure the flow of filler sucked in during the drying process. There is no sensor on the market that are guaranteed to measure a large concentration of dust (200,000 mg/m3) in suspension at high temperatures (150-200ºC).
Within the framework of the project, a solution to this problem has been developed, you can consult the laboratory results in the research article recently published in the scientific journal Sensors (“Vibration-Based Smart Sensor for High-Flow Dust Measurement”)
The development of this type of sensors requires various laboratory tests to be carried out under controlled conditions to verify the feasibility of this solution and then, also under laboratory conditions, to carry out calibrated tests to ensure that it is possible to estimate the true flow of filler sucked in during the sand drying process. CAPRI Project has successfully completed the testing of this sensor and others belonging to the manufacture of steel bars and pharmaceutical pills.
The Project in its commitment to the open science initiative promoted by the European Commission has published in its Zenodo channel, different results of these laboratory tests that allow us to corroborate the preliminary success of these sensors pending their validation and testing in the productive areas of the project partners. In the near future we will be able to share the results of the industrial operation of this and other sensors developed in the project.
Co-author
Cristina Vega Martínez. Industrial Engineer. Coordinator at CAPRI H2020 Project
The impact of Artificial Intelligence (AI) is highly recognized as a key driver of the industrial digital revolution together with data and robotics 1 2. To increase AI deployment that is practically and economically feasible in industrial sectors, we need AI applications with more simplified interfaces, without requiring highly skilled workforce but exhibiting longer useful life and requiring less specialized maintenance (e.g. data labelling, training, validation…)
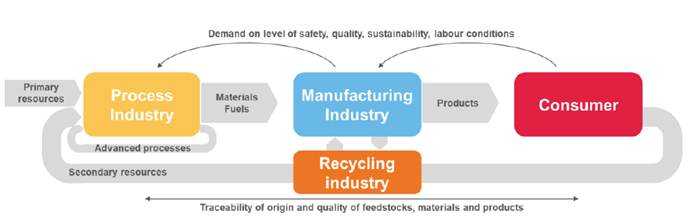
Achieving an effective deployment of trustworthy AI technologies within process indsutries needs a coherent understanding of how these different technologies complement and interact with each other in the context of domain-specific requirements that industrial sectors require3, such as process industries who must leverage the potential of innovation driven by digital transformation, as a key enabler for reaching Green Deal objectives and expected twin green and digital transition needed for a full evolution towards circular economy.
One of the most important challenges for developing innovative solutions in the process industry is the complexity, instability and unpredictability of their processes and impact into their value chains. These solutions usually require: running in harsh conditions, under changes in the values of process parameters, missing a consistent monitoring/measurement of some parameters important for analysing process behaviour and difficult to measure in real time. Sometimes, such parameters are only available through quality control laboratory analysis that are responsible to get the traceability of origin and quality of feedstocks, materials and products.
For AI-based applications, these are even more critical constraints, since AI requires (usually) a considerable amount of high-quality data to ensure the performance of the learning process (in terms of precision and efficiency). Moreover, getting high quality data usually requires an intensive involvement of human experts for curating (or even creating) the data in a time-consuming process. In addition, a supervised learning process requires labelling/classifying the training examples by domain experts, which makes an AI solution not cost-effective.
Minimizing (as much as possible) human involvement in the AI creation loop implies some fundamental changes in the organizations of the AI process/life-cycle, especially from the point of view of achieving a more autonomous AI, which leads to the concept of self-X AI4 . To achieve such autonomous behaviour for any kind of application it usually needs to exhibit advanced (self-X) abilities like the ones proposed for the autonomic computing (AC)5:
Self-X Autonomic Computing abilities
Self-Configuration (for easier integration of new systems for change adaptation)
Self-Optimization (automatic resource control for optimal functioning)
Self-Healing (detection, diagnose and repair for error correction)
Self-Protection (identification and protection from attacks in a proactive manner)
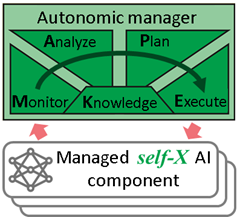
AutonomicComputing paradigm can support many AI tasks with an appropiate management, as already reported in the scientific community 6 7 . In AI acts as the intelligent processing system and the autonomic manager (continuously executes a loop of monitoring-analyzing-planning-executing based on the knowledge (MAPE-K) of the AI system under control for developing a self-improving AI application.
Indeed, such new (self-X) AI applications will be, to some extent, self-managed to improve their own performance incrementally5. This will be realized by an adaptation loop, which enables “learning by doing” using MAPE-K model and self-X abilities as proposed by autonomic computing. The improvement process should be based on continuous self-Optimization ability (e.g. hyper-parameter tuning in Machine Learning). Moreover, in the case of having some problems in the functioning of an AI component, the autonomic manager should activate self-Configuration (e.g. choice of AI method), self-Healing (e.g. detecting model drify) and self-Protection abilities (e.g. generating artificial data to improve trained models) as needed, based on knowledge from AI system.
In just a few weeks, CARTIF will start a project with the help of AI experts and leading companies of various process industry sectors across Europe to tackle these challenges and close the gap between the AI and automation by proposing a novel approach for a continuous update of AI applications with minimal human expert intervention, based on an AI data pipeline, which exposes autonomic computing (self-X) abilities, so called self-X AI. The main idea is to enable the continuous update of AI applications by integrating industrial data from physical world with reduced human intervention.
We’ll let you know in future posts about our progress with this new generation of self-improving AI applications for the industry.
Computer vision is a discipline that has made it possible to control different production processes in industry and other sectors for many years. Actions as common as the shopping process in a supermarket require vision techniques such as scanning barcodes.
Until a few years ago, many problems could not be solved in a simple way with classical vision techniques. Identifying people or objects located at different positions in images or classifying certain types of inhomogeneous industrial defects were highly complex tasks that often did not provide accurate results.
Advances in Artificial Intelligence (AI) have also accompanied the field of vision. While Alan Turing established the Turing test in 1950, where a person and a machine were placed behind a wall, and another person asked questions trying to discover who was the person and who was the machine, in computer vision through AI, systems capable of reproducing the behaviour of humans are sought.
One of the fields of AI is neural networks. Used for decades, it was not unitl 2012 that they began to play an important role in the field of vision. AlexNet1 , designed by Alex Krizhevsky, was one of the first networks to implement the 8-layer convolution filter design. Years earlier, a worldwide championship had been established where the strongest algorithms tried to correctly classify images from ImageNet2 , a database with 14 million images representing 1,000 different categories. While the best of the classical algorithms, using SIFT and Fisher vectors, achieved 50.9% accuracy in classifying ImageNet images, AlexNet brought the accuracy to 63.3%. This result was a milestone and represented the beginning of the exploration of Deep Learning (DL). Since 2012, the study of deep neural networks has deepened greatly, creating models with more than 200 layers of depth and taking ImageNet´ s classification accuracy to over 90% with the CoAtNet3 model. which integrates convolution layers with attention layers in an intelligent, deep wise way.
Turning to the relationship of modern computer vision models to AI, Dodge et. al (2017)4 found that modern neural networks classifying ImageNet images made fewer errors than humans themselves, showing that computer systems are capable of doing tasks better and much faster than people.
Among the most common problem solved by computer vision using AI are: image classification, object detection and segmentation, skeleton recognition (both human and object), one shot learning, re-identification, etc. Many of the problems are solved in two dimensions as well as in 3D.
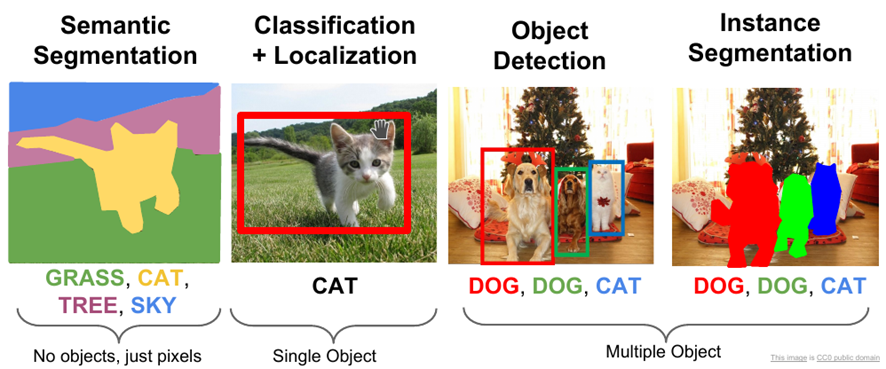
Various vision problems solved by AI: Segmentation, classification, object detection
Classification simply tells us what an image corresponds to. So for example, a system could tell whether an image has a cat or a dog in it. Object detection allows us to identify several objects in an image and delimit the rectangle in which they have been found. For example, we could detect several dogs and cats. Segmentation allows us to identify the boundaries of the object, not just a rectangle. There are techniques that allow us to segment without knowing what is being segmented, and techniques that allow us to segment knowing the type of object we are segmenting, for example a cat.
Skeletal recognition allows a multitude of applications, ranging from security issues to the recognition of activities and their subsequent reproduction in a robot. In addition, there are techniques to obtain key points from images, such as points on a person´ s face, or techniques to obtain three-dimensional orientation from 2D images.
Industry segmentation using MaskRCNN5
One Shot Learning allows a model to classify images from a single known sample of the class. This technique, typically implemented with Siamese neural networks, avoids the need to obtain thousands of images of each class to train a model. In the same way, re-identification systems are able to re-identify a person or object from a single image.
The high computational cost of DL models led early on to the search for computational alternatives to CPUs, the main processors in computers. GPUs, or graphics processing units, which were originally developed to perform parallel computations for smoothly generating images for graphics applications or video games, proved to be perfectly suited to parallelising the training of neural networks. In neural network training there are two main stages, forward and back-propagation. During the forward process, images enter the network and pass through successive layers that apply different filters in order to extract salient features and reduce dimensionality. Finally, one or more layers are responsible for the actual classification, detection or segmentation. In backward propagation, the different parameters and weights used by the network are updated, in a process that goes from the output, comparing the obtained and expected output, to the input. The forward process can be parallelised by creating batches of images. Depending on the memory size of the GPUs, copies of the model are created that process all images in a batch in parallel. The larger the batch size we can process, the faster the training will be. This same mechanism is used during the inference process, a process that also allows parallelisation to be used. In recent years, some cloud providers have started to use Tensor Processing Units (TPUs), with certain advantages over GPUs. However, the cost of using these services is often high when performing massive processing.
Skeleton acquisition, activity recognition and reproduction on a Pepper robot6
CARTIF has significant deep neural network training systems, which allows us to solve problems of high computational complexity in a relatively short time. In addition, we have refined several training algorithms using the latest neural networks7 . We have also refined One Shot Learning systems using Siamese networks8. We also use state-of-the-art models in tasks such as object and human recognition, segmentation and detection, image classification, including industrial defects, and human-robot interaction systems using advanced vision algorithms.
1Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems, 25.
2Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., … & Fei-Fei, L. (2015). Imagenet large scale visual recognition challenge. International journal of computer vision, 115(3), 211-252.
3Dai, Z., Liu, H., Le, Q., & Tan, M. (2021). Coatnet: Marrying convolution and attention for all data sizes. Advances in Neural Information Processing Systems, 34.
4 Dodge, S., & Karam, L. (2017, July). A study and comparison of human and deep learning recognition performance under visual distortions. In 2017 26th international conference on computer communication and networks (ICCCN) (pp. 1-7). IEEE.
5He, K., Gkioxari, G., Dollár, P., & Girshick, R. (2017). Mask r-cnn. In Proceedings of the IEEE international conference on computer vision (pp. 2961-2969).
6Domingo, J. D., Gómez-García-Bermejo, J., & Zalama, E. (2021). Visual recognition of gymnastic exercise sequences. Application to supervision and robot learning by demonstration. Robotics and Autonomous Systems, 143, 103830.
7Domingo, J. D., Aparicio, R. M., & Rodrigo, L. M. G. (2022). Cross Validation Voting for Improving CNN Classification in Grocery Products. IEEE Access.
8Duque Domingo, J., Medina Aparicio, R., & González Rodrigo, L. M. (2021). Improvement of One-Shot-Learning by Integrating a Convolutional Neural Network and an Image Descriptor into a Siamese Neural Network. Applied Sciences, 11(17), 7839.