Imagina que cada producto que llega a tus manos pudiera explicarte su historia: de dónde viene, con qué materiales se fabricó, qué procesos atravesó, cómo se garantizó su calidad y bajo qué condiciones fue transportado hasta su destino.
Vivimos en una era en la que la información lo es todo. Sin embargo, en el mundo industrial aún dejamos que muchos datos valiosos se pierdan entre sistemas aislados y decisiones urgentes. ¿Y si pudiéramos hacer que esos datos fueran visibles, útiles y conectados?
Hoy, gracias a tecnologías como la Industria 4.0 o los sistemas de captura en tiempo real, las plantas de producción generan más información que nunca. Pero tener datos no basta. La clave está en estructurarlos, interpretarlos y relacionarlos. Convertir datos dispersos en conocimiento útil es el primer paso hacia un etiquetado digital realmente inteligente.
Esto es precisamente lo que se busca en el proyecto europeobiOSpace: desarrollar un sistema de etiquetado digital para productos bio-basados que permita seguir el rastro de cada lote desde su origen hasta su entrega. Este sistema no solo recogerá información técnica sobre materias primas, procesos y controles de calidad, sino que también incluirá datos logísticos, condiciones de transporte y métricas medioambientales.
¿Por qué es necesario el etiquetado digital?
En los procesos industriales actuales, gran parte de la información clave sobre la fabricación de un producto se encuentra dispersa en distintas plataformas o no se registra de forma estructurada. Esto dificulta la trazabilidad completa de lo que ocurre en planta y, en consecuencia, complica la toma de decisiones operativas, la mejora continua o la justificación de estándares de sostenibilidad y calidad. En el contexto de la producción bio-basada, donde los materiales pueden variar en función del proveedor, la cosecha o el proceso, tener control sobre cada etapa del ciclo de vida del producto se vuelve especialmente importante. De ahí la necesidad de establecer un sistema que permita recopilar y consultar toda esta información de forma unificada y accesible.
¿Qué tipo de información se recopilará?
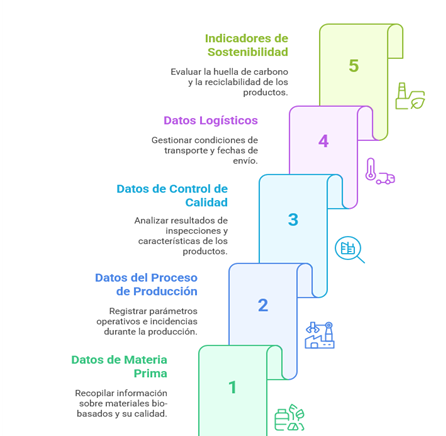
El sistema de etiquetado digital que se está diseñando en biOSpace contempla cinco bloques de información esenciales:
Todos estos datos se vinculan mediante un identificador digital único que acompaña al producto a lo largo de todo su recorrido, desde su entrada en fábrica hasta su salida. Esta etiqueta se va completando progresivamente, añadiendo información a medida que el producto atraviesa diferentes etapas del proceso: recepción de materia prima, transformación, control de calidad, embalaje, transporte, etc.
Esta estructura modular del identificador permite trazar con precisión el recorrido y condiciones del producto en cada fase, haciendo que toda la información relevante esté conectada de forma clara y estructurada.
¿Qué se puede lograr gracias a una trazabilidad integral?
El valor de esta información no reside solo en almacenarla, sino en poder utilizarla de forma práctica y adaptada a cada necesidad. Por eso, uno de los objetivos es que el sistema pueda consultarse desde paneles internos que ayuden al personal de planta a tomar decisiones en tiempo real, y que al mismo tiempo pueda integrarse en entornos digitales más amplios, como sistemas de gestión o plataformas de gemelo digital.
Además, la misma etiqueta digital puede ofrecer diferentes niveles de información según el perfil del usuario que la consulta. Un operario podrá ver datos técnicos sobre el proceso o los controles de calidad, mientras que un responsable de sostenibilidad podrá acceder a indicadores ambientales, y un consumidor final podrá consultar un resumen accesible sobre el origen del producto, sus características y su trazabilidad.
Esta trazabilidad detallada permitirá también alimentar lo que ya empieza a conocerse como pasaporte digital de producto, una herramienta que gana relevancia en el marco de las políticas europeas hacia una economía circular y más transparente.
«Lo que hacemos hoy con nuestros datos marca el rumbo de lo que haremos mañana con nuestros productos»
Aunque esta solución todavía se encuentra en fase de diseño, parte de una pregunta sencilla pero importante: ¿qué estamos haciendo con toda la información que ya se genera en nuestras fábricas?
En muchos casos, los datos existen, pero no están conectados, no se comparten o simplemente no se utilizan. Este proyecto busca precisamente eso: darles sentido, organizarlos y ponerlos al servicio de quienes los necesitan, desde el operario que gestiona un lote hasta quien toma decisiones estratégicas o quien, al final de la cadena, consume el producto.
No se trata de incorporar tecnología por tendencia, sino de usarla con criterio. De construir herramientas que permitan entender mejor lo que producimos, cómo lo hacemos y con qué impacto, en un momento en el que la trazabilidad, la sostenibilidad y la transparencia ya no son opciones, sino condiciones para seguir avanzando.
En el mundo del desarrollo de software, la interoperabilidad es la capacidad de que diferentes dispositivos, sistemas y aplicaciones trabajen juntos de manera coordinada, como si fueran músicos en la orquesta sinfónica de Viena, independientemente de su origen o tecnología. Este concepto es clave en la transformación digital donde los sistemas, como por ejemplo, una aplicación robótica, deben integrarse con múltiples plataformas, incluyendo sistemas de control robotizados, soluciones de inteligencia artificial y plataformas de gestión industrial IT como el ERP (Planificación de Recursos Empresariales) o MES (Sistema de Ejecución de Fabricación).
El objetivo principal es facilitar el intercambio de datos en tiempo real para una toma de decisiones más inteligente. La interoperabilidad desempeña un papel esencial en la robótica al permitir la integración fluida entre sistemas productivos industriales heterogéneos y plataformas digitales.
Beneficios de la interoperabilidad
Adoptar tecnologías de interoperabilidad en el desarrollo de aplicaciones robóticas aporta múltiples ventajas, entre ellas:
Gestión inteligente y monitorización remota de activos como robots y máquinas herramienta, permitiendo un control centralizado y en tiempo real de sistemas distribuidos.
Optimización de la toma de decisiones, gracias a la disponibilidad de datos en tiempo real, se asegura una mejor capacidad de respuesta a eventos imprevistos y optimización de flujos de trabajo.
Facilidad de escalabilidad y modularidad: permitiendo la integración de nuevas tecnologías, sensores y robots sin la necesidad de rediseñar sistemas completos, favoreciendo la adaptabilidad de futuras necesidades industriales.
Reducción de costes y tiempos de inactividaden líneas de producción, gracias a la integración de sistemas heterogéneos, minimizando tiempos de configuración y permitiendo una rápida reconfiguración y flexibilidad de procesos productivos en entornos dinámicos.
Mantenimiento predictivo y optimización de recursos, utilizando modelos basados en IA para anticipar fallos, optimizar el uso de repuestos y aumentar la vida útil de los equipos sin comprometer la productividad.
FIWARE como facilitador de la interoperabilidad
Para que los sistemas robóticos puedan integrarse de manera eficiente, es crucial que sean compatibles con plataformas estandarizadas que permitan la gestión inteligente de datos y la comunicación. FIWARE, con la que trabajamos en el proyecto ARISE, es un conjunto de tecnologías, arquitecturas, y estándares que aceleran el desarrollo e implantación de soluciones basadas en código abierto. Como tecnología referente para la Unión Europea, FIWARE contribuye principalmente a la creación de herramientas y servicios interoperables para la gestión y análisis de datos en tiempo real, asegurando persistencia, flexibilidad y escalabilidad, permitiendo así la creación de aplicaciones personalizadas sin costes excesivos. Otra propuesta de valor es su naturaleza multi-sector. Los componentes y arquitecturas de referencia estandarizados de FIWARE permiten que cualquier solución diseñada para un sector específico de la industria productiva, logística o servicios, sea por defecto interoperable con otro tipo de verticales como la gestión de energía, movilidad, o los emergentes espacios de datos.
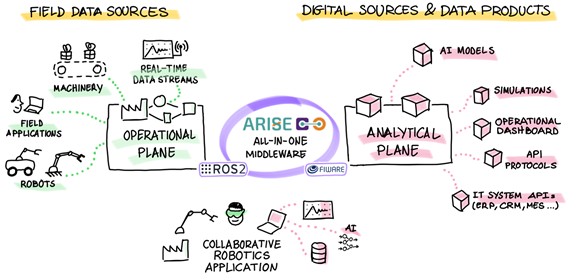
En ARISE, desarrollamos aplicaciones robóticas para la interacción humano-robot integrando nuestro ARISE middleware (solución middleware que integra Vulcanexus, ROS2, FIWARE y ROS4HRI), en cuatro entornos de experimentación explorando soluciones robóticas conectadas con FIWARE en un escenario de industria 5.0. Uno de estos entornos está en CARTIF, un laboratorio para pruebas de validación tecnológica en entornos de prueba controlados (TRL 4-5). En la siguiente Figura 1 se puede ver este entorno de experimentación:
Fig 1. Entorno de experimentación en CARTIF
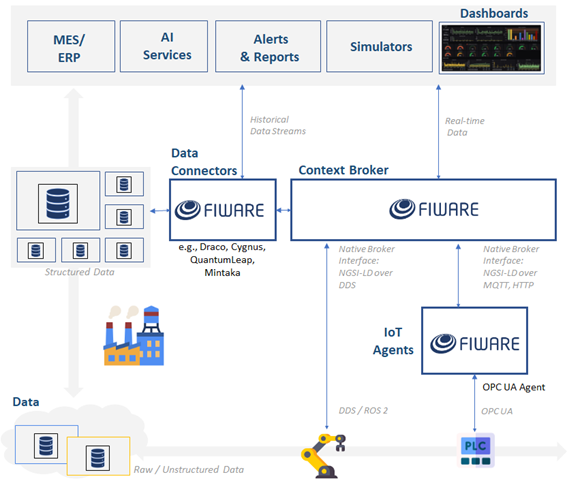
El papel fundamental de FIWARE radica en proporcionar herramientas que permitan la interoperabilidad entre sistemas heterogéneos, asegurando una integración fluida de datos y dispositivos IoT en tiempo real, una gestión dinámica de los datos procedentes del plano operacional permitiendo la comunicación entre diferentes sistemas, dispositivos y plataformas hacia el plano analítico, garantizando una integración profunda con las infraestructuras IT/OT empresariales (ver figura 2):
Fig 2. Ecosistema ARISE middleware
Cómo se diseña una arquitectura FIWARE y componentes clave
El diseño de una arquitectura FIWARE se basa en un enfoque modular, donde los componentes se integran según las necesidades de la aplicación. La arquitectura se organiza en torno a su núcleo central (Context Broker) que gestiona el tránsito de los datos en tiempo real. Para implementar FIWARE de manera efectiva, se recomienda seguir estos pasos:
Definir el caso de uso: identificar los objetivos y requisitos de la aplicación
Seleccionar la arquitectura adecuada: incluir el Context Broker, IoT Agents y otros componentes según las necesidades, convertir protocolos heterogéneos en datos compatibles con FIWARE. Por ejemplo, el habilitador OPC-UA IoT Agent, facilita que los datos recopilados en entornos industriales puedan gestionarse en tiempo real, facilitando la interoperabilidad con otros sistemas.
Integrar dispositivos y sistemas: conectar sensores, robots u otros sistemas mediante OPC-UA, MQTT u otros protocolos.
Implementar seguridad y control de acceso: usar Keyrock y PEP Proxy para garantizar la protección de datos gestiona la autenticación y control de acceso.
Almacenar y analizar datos: utilizar Cygnus, Draco o QuantumLeap para obtener información valiosa, para el almacenamiento histórico de datos, persistencia y su análisis en plataformas Big Data.
Desplegar en la nube o en entornos locales: considerar FIWARE Lab o infraestructura propia para el hosting de los servicios.
Monitorización y Optimización: evaluar el rendimiento del sistema y mejorar la integración con otras plataformas como AI-on-Demand o Digital Robotics. Wirecloud permite la creación de dashboards visuales personalizados. También facilita la conexión con otras aplicaciones de fácil integración como Grafana y Apache Superset.
Fig 3. FIWARE arquitectura modulas y ejemplo de aplicación
En CARTIF seguimos apostando por estas tecnologías para construir un futuro donde la colaboración entre sistemas y plataformas sea la clave del éxito. Recientemente nos hemos unido a la red de FIWARE iHubs con el nombre de CARTIFactory. Como iHub oficial, no solo fomentará la adopción de FIWARE, sino que también actuará como un centro de referencia con su laboratorio de experimentación para fomentar la interoperabilidad en aplicaciones robóticas de nuestra comunidad y ecosistema industrial.
En conclusión, la interoperabilidad no es solo un requisito técnico sino un pilar fundamental para el éxito de la transformación digital en la industria. Tecnologías como FIWARE permiten conectar sistemas, optimizar procesos y fomentar un ecosistema , flexible y escalable Gracias a esta capacidad, las empresas pueden integrar inteligencia artificial, robótica y automatización avanzada.
Co-autores
Aníbal Reñones. Director del área de Industria 4.0 de la División de Sistemas Industriales y Digitales.
Francisco Meléndez. Experto en Robótica y FIWARE Evangelista. Technical Coordinator en el proyecto ARISE (FIWARE Foundation).
La inteligencia artificial (IA) ha dejado de ser una mera fantasía futurista para integrarse de manera tangible en nuestra vida cotidiana. Desde las recomendaciones personalizadas en plataformas de streaming hasta la optimización de los procesos logísticos en una fábrica, la IA está en todas partes. Lo interesante es que no solo está haciendo nuestras vidas más cómodas, sino que también está transformando la industria.
En el proyecto HUMAIN, donde colaboramos con empresas como BAMA y CENTUM, estamos llevando la IA al siguiente nivel. Imagina una fábrica que puede anticipar problemas antes de que ocurran, gracias a sistemas predictivos basados en datos. O robots que trabajan junto con humanos para embalar y paletizar productos de manera eficiente, incluso cuando las cajas tienen tamaños diferentes. ¡Es como pasar de un coche manual a uno automático!
Pero esto no es ciencia ficción. Estamos investigando y desarrollando algoritmos de inteligencia artificial que convierten datos masivos en decisiones inteligentes, sistemas de visión por computador que ven más allá de lo que el ojo humano puede detectar y soluciones de mantenimiento predictivo impulsadas por aprendizaje automático que ahorran tiempo y dinero. La IA actúa como un cerebro estratégico que optimiza cada aspecto del proceso, desde la producción hasta la logística. ¿El resultado? Procesos más sostenibles, menos residuos y fábricas más inteligentes.
Este tipo de proyectos no solo benefician a las grandes empresas. También tienen un impacto directo en nuestras vidas. Piénsalo: cada vez que compras algo en línea y llega a tu puerta en tiempo récord, es probable que detrás haya un sistema de IA que optimizó cada paso del proceso. Desde el empaquetado hasta la entrega.
El consorcio del proyecto HUMAIN, estamos emocionados de ser parte de esta revolución. No se trata solo de hacer que las máquinas trabajen más rápido, sino de integrar tecnologías disruptivas que conviertan a las personas en el corazón del proceso. Porque al final, la IA es una herramienta: lo importante es cómo la usamos para mejorar nuestro día a día.
¿Estamos listos para abrazar esta revolución industrial? La respuesta está en cada clic, cada compra y cada robot que trabaja codo a codo con nosotros.
La inteligencia artificial (IA) está contribuyendo a la transformación de un gran número de sectores, desde sugerir una canción de música hasta analizar el estado de nuestra salud con el reloj, pasando por la industria de la fabricación. Un freno a esta transformación es la complejidad de los sistemas de IA usados, lo que a menudo plantea desafíos en términos de transparencia y comprensión de los resultados que ofrecen. En este contexto, se habla de la capacidad de explicación – o “explicabilidad” – de la IA como la capacidad para hacer comprensibles sus decisiones y acciones a los usuarios – es lo que se conoce como IA explicable, o XAI por sus siglas en inglés; algo que es crucial para generar confianza y asegurar una adopción responsable de la tecnología.
Explicabilidad de la IA; capacidad para hacer comprensibles sus decisiones y acciones a los usuarios.
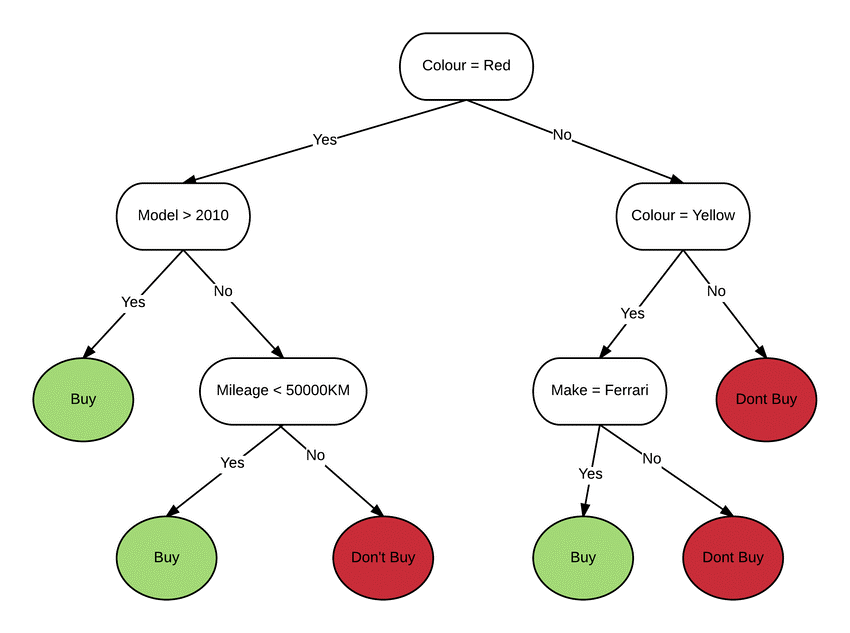
En la actualidad, se trabaja en un amplio abanico de soluciones tecnológicas para mejorar la explicabilidad de los algoritmos de IA. Una de las principales estrategias incluye la creación de modelos intrínsecamente explicables (ante hoc). Estos modelos, como por ejemplo los árboles de decisión y las reglas de asociación, están diseñados para ser transparentes y comprensibles por naturaleza. Su estructura lógica permite a los usuarios seguir fácilmente el razonamiento detrás de las decisiones. Las herramientas de visualización de explicaciones son clave, ya que representan gráficamente el proceso de toma de decisiones del modelo, facilitando su comprensión por parte de los usuarios. Éstas pueden incluir desde cuadros de mando dedicados hasta gafas de realidad aumentada, pasando por explicaciones en lenguaje natural (por voz o texto).
Sistema intrínsecamente explicable: árbol de decisión. Los nodos intermedios son condiciones que verifican progresivamente hasta llegar a la respuesta final; la secuencia de condiciones es la explicación.
Explicación en lenguaje natural de un sistema de recomendación de nuevas rutas para hacer ejercicio. Extraida de Xu et al. (2023). XAIR: framework of XAI in augmented reality.
Otra familia de técnicas de explicación comúnmente utilizada es la de los métodos post hoc: éstos consisten en, una vez creado un modelo de IA complejo, procesar y analizar a posteriori el propio modelo resultante para explicar sus resultados. Por ejemplo, algunas de estas técnicas evalúan cuánto contribuye cada variable en la respuesta final del sistema (análisis de sensibilidad). Entre las técnicas de explicabilidad post hoc destaca SHAP (SHapley Additive exPlanations), un método basado en la teoría de juegos cooperativos, que permite extraer coeficientes que determinan la importancia de cada variable de entrada en el resultado final del algoritmo de IA.
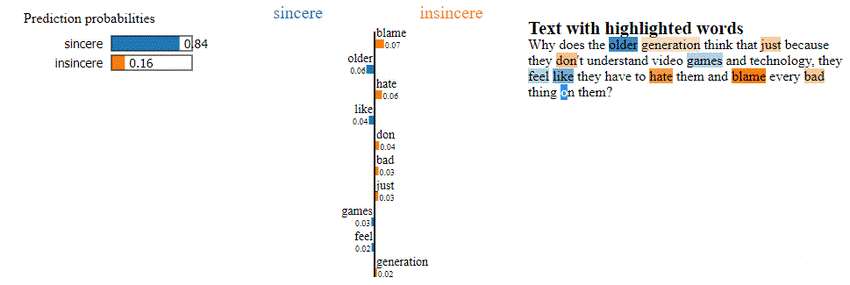
Otras técnicas incluyen la descomposición, que divide el modelo de IA en componentes más simples y más fácilmente explicables, y la destilación en modelos subrogados (knowledge distillation, surrogate models) que aproximan la función del sistema original, pero son más fácilmente comprensibles. Por otro lado, las llamadas “explicaciones locales” consisten en métodos que explican ejemplos individuales (entrada-salida), no el modelo completo. Un ejemplo son las explicaciones proporcionadas por herramientas como LIME (Local Interpretable Model-agnostic Explanations). En el ejemplo de la siguiente figura se explican las palabras más relevantes para determinar por qué el texto se considera ‘sincero’ (con un 84% de fiabilidad) o ‘insincero’ [Linardatos et al. (2020)].
Un enfoque adicional es la integración de entradas de usuarios en el proceso de construcción del modelo, conocido como «Human-in-the-Loop» (HITL). Este enfoque permite a los usuarios interactuar (e.g. etiquetando datos nuevos) y supervisar los algoritmos de IA, ajustando sus decisiones en tiempo real y mejorando así la transparencia del sistema.
En CARTIF, se está trabajando activamente en diferentes proyectos relacionados con IA, como s-X-AIPI para avanzar en la explicabilidad de los sistemas de IA usados para aplicaciones industriales. Un ejemplo significativo de nuestro trabajo son los dashboards (paneles de visualización o cuadros de mando) diseñados para la supervisión y análisis del rendimiento de los procesos de fabricación estudiados en el proyecto. Estos dashboards permiten a los operadores de planta visualizar y entender cómo se está desempeñando el proceso en tiempo real.
Se han creado modelos predictivos y de detección de anomalías para la industria del asfalto que no solo anticipan valores futuros, sino que también detectan situaciones inusuales y explican los factores influyentes en estas predicciones y detecciones. De esta manera, se ayuda a los operarios a tomar decisiones informadas y a entender mejor los resultados generados por los sistemas de IA y como deben actuar.
La explicabilidad en métodos de IA es esencial para su adopción segura y efectiva en todo tipo de sectores: industria, ventas, logística, farmacia, construcción…. En CARTIF, estamos comprometidos con el desarrollo de tecnologías para crear aplicaciones basadas en Inteligencia Artificial que no sólo mejoren los procesos y servicios, sino que también sean transparentes y comprensibles para los usuarios, en definitiva, que sean explicables.
Co-autor
Iñaki Fernández. Doctor en Inteligencia Artificial. Investigador en el área de Salud y Bienestar de CARTIF
Imagina descubrir que el piloto de tu próximo vuelo estará usando el Apple Vision Pro mientras está al mando del avión. ¿Te sentirías cómodo subiendo a ese avión? Si tu respuesta es no, es posible que pienses que el piloto es un imprudente y tu vida está en riesgo. Por otro lado, si respondes si, es probable que conozcas el potencial de emplear este dispositivo en dicha situación.
Recientemente el mundo se vio envuelto en este debate cuando un piloto en Estados Unidos fue grabado usando el Apple Vision Pro durante un vuelo. El piloto en cuestión afirmaba haber mejorado su productividad con este dispositivo1. Sin embargo, recibió críticas significativas y tuvo que disculparse tras eliminar el vídeo.
¿Por qué este caso indignó tanto? En realidad, son muchos los sectores donde se utilizan este tipo de dispositivos diariamente, como la cirugía, la arquitectura, la ingeniería y la formación. La razón es simple: estamos progresando.Aunque los humanos somos escépticos ante nuevas tecnologías, reconocemos que pueden mejorar nuestras vidas. Un ejemplo claro es el comercio electrónico; cuando comenzó, muchas personas pensaban que era peligroso. Ahora, Amazon es la quinta empresa más valiosa de Estados Unidos y en España, el 39% de la población compra de manera online al menos una vez al mes2.
Es probable que con el tiempo este sentimiento también se disipe en el caso de la realidad extendida. Este término, que engloba la realidad virtual, realidad aumentada y realidad mixta, puede resultar confuso para muchos. Cada tecnología tiene un propósito específico basado en el nivel de inmersión: la realidad virtual crea entornos completamente digitales, la realidad aumentada superpone elementos digitales en la realidad física y la realidad mixta combina ambas para dar conciencia espacial a los elementos digitales. Este concepto comprende mejor si se observa la siguiente imagen.
Diferencias entre realidad virtual, aumentada y mixta. Fuente: Avi Barel3
En la imagen, se puede apreciar cómo en realidad mixta, un objeto como un pato de goma puede reconocer su entorno y posicionarse detrás de una mesa en lugar de atravesarla como lo haría en realidad aumentada. ¡Esta es la magia de la realidad mixta!
Aunque el Apple Vision Pro tiene características increíbles, dispositivos similares existen desde hace tiempo, algo que en CARTIF se sabe bien. Por eso, desde hace tiempo en la División de Sistemas Industriales y Digitales empleamos el dispositivo de realidad mixta Microsoft HoloLens 2, para cumplir diversos propósitos.
En el proyecto Baterurgia, estamos usando esta tecnología para automatizar el desmontaje de baterías de coches eléctricos y, favoreciendo la interacción humano-robot. Para lograrlo. nos apoyamos en la robótica y la visión artificial para detectar los tornillos presentes en una batería. A través de las lentes del Microsoft Hololens 2, el operario observa hologramas que indican la posición de los tornillos en el espacio. El operario puede seleccionar un tornillo con el dedo o la mirada y dar órdenes al robot mediante comandos de voz. El sistema ofrece retroalimentación sobre el progreso de la actividad, permitiendo que el operario realice otras tareas simultáneamente.
Secuencia de recogida de un tornillo (Grabado con Microsoft HoloLens 2)
Visualización de la imagen de la cámara con los tornillos detectados.
Señalización de los tornillos.
El operario elige un tornillo.
El robot recoge el tornillo elegido.
Como has visto, la realidad mixta está ganando popularidad y se está aplicando en más sectores. El alto costo de productos como Apple Vision Pro y Microsoft Hololens 2, que rondan los $3500, es una limitación importante. No obstante, nuevos dispositivos más asequibles como Meta Quest 3, que cuesta alrededor de $500, están haciendo que esta tecnología sea más accesible para empresas y usuarios. En esta línea, se prevé que la cantidad de ventas mundiales de dispositivos de realidad extendida aumente a 105 millones para 20254.
Si este post te ha intrigado y deseas explorar más sobre la realidad extendida y su impacto, ¡Estaré encantado de compartir más información contigo!
Cuando un proyecto finaliza, es el momento de recapitular, de recopilar toda la información y la experiencia adquirida durante el proceso. A lo largo de los tres años y medio de trabajo en el proyecto CAPRI, ha habido mucho tiempo para hacer cosas, para obtener muy buenos resultados o para sentirse mal porque muchas veces nada parece funcionar bien a la primera.
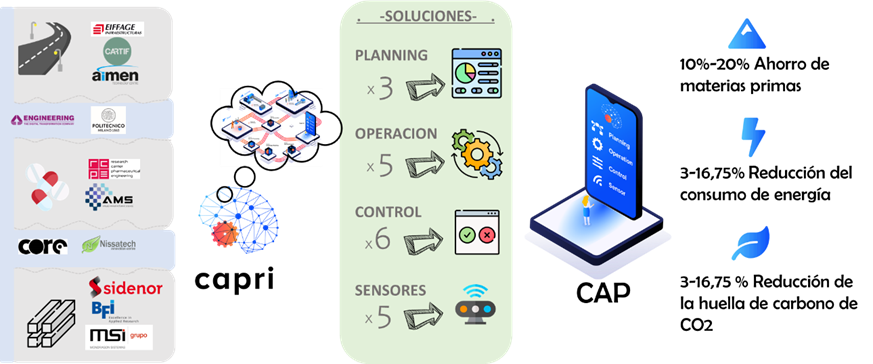
El proyecto CAPRI finalizó en septiembre de 2023 y logró sus principales objetivos definidos al inicio, que fueron impulsados por la necesidad de ayuda en la transformación digital de la industria europea de procesos mediante la investigación, desarrollo y prueba de una plataforma de automatización cognitiva, CAP, que integra 19 soluciones cognitivas diferentes definidas en cada una de las tres plantas piloto del proyecto. Esta plataforma se ha diseñado para lograr el objetivo final de obtener reducciones en el uso de materias primas, consumo de energía y huella de CO2. Tras finalizar el proyecto, se ha demostrado que las reducciones se han logrado gracias a la estrecha colaboración de los doce socios involucrados, procedentes de siete países diferentes. La plataforma cognitiva y las soluciones se implementaron en tres sectores importantes de la industria de procesos: fabricación de asfalto, producción de lingotes y barras de acero y producción de tabletas en la industria farmacéutica.
Por ejemplo, en la planta piloto de asfalto de EIFFAGEInfraestructuras, las soluciones cognitivas estaban relacionadas con los cuatro niveles de automatización, desde sensores hasta planificación, abarcándolos todos. El prototipo final demostrado bajo operación real de la planta de asfalto incluyó tecnologías muy diferentes como visión por computadora, análisis de vibraciones, redes neuronales o modelos matemáticos para la parametrización de los datos existentes para predecir los indicadores clave de rendimiento (consumo específico de energía por tonelada de mezcla de asfalto o la cantidad final de materias primas utilizadas).
Las soluciones cognitivas desarrolladas, como el control cognitivo del tambor secador o los nuevos sensores, aseguran la calidad de los productos y la producción en tiempo real, reduciendo el consumo de energía y materias primas utilizadas. Antes del proyecto, el control de los materiales utilizados se basaba en estimaciones y ahora, con el modelo matemático para el balance de masas y los nuevos sensores, los operadores de la planta pueden recibir una información en tiempo real que no tenían antes.
Los resultados esperados de cada solución cognitiva se definieron durante las primeras etapas del proyecto para verificar las mejoras de cada una durante el período de validación del proyecto. El proyecto CAPRI ofrece soluciones innovadoras que tienen el potencial de transformar industrias e impulsar el progreso. Destaca el enfoque del proyecto en desbloquear nuevas posibilidades y capacitar a varios sectores con avances de vanguardia gracias a los resultados explotables clave generados.
Respecto a estos resultados, dentro del caso de uso de asfalto, se incluyeron como resultados explotables tres soluciones: un sensor para medir el polvo aspirado en línea dentro de un tubo, la cantidad de betún presente en el asfalto reciclado y un sistema de mantenimiento predictivo del colector de polvo de la planta basado en sensores cognitivos y conocimientos expertos. El caso de uso del acero generó dos resultados explotables: un sensor cognitivo de solidificación de acero para procesos de colada continua y un seguimiento de productos de acero. El caso de uso de la industria farmacéutica tiene dos resultados explotables: un sensor cognitivo para la calidad de los gránulos y un sensor de atributos de calidad.
El proyecto también generó algunos resultados explotables clave transversales útiles para cualquier tipo de industria: la arquitectura técnica de la plataforma de automatización cognitiva o CAP, y otro relacionado con los datos abiertos generados, mostrando el compromiso del proyecto CAPRI con la ciencia abierta y los principios FAIR a través de la generación de más de 50 activos compartidos en plataformas abiertas, como Zenodo.
Los principales objetivos de la propuesta fueron la reducción del uso de materias primas, energía y huella de CO2. Podemos decir con orgullo que logramos esos objetivos, como se puede ver en la tabla resumen de KPIs después de CAPRI:
KPI Objetivo
Después de CAPRI
5% – 20% Ahorro de materias primas
10-20%
5% reducción del consumo de energía
3-16,75%
5% reducción de la huella de carbono de CO2
3-16,75%
Como ingeniero, cuando un proyecto finaliza a tiempo, y con estos muy buenos resultados, cuando su proyecto ha contribuido a mejorar la industria, sin dañar nuestro medio ambiente, uno se siente mejor y todos los sacrificios, horas extras y críticas negativas valieron la pena.