La inteligencia artificial (IA) está contribuyendo a la transformación de un gran número de sectores, desde sugerir una canción de música hasta analizar el estado de nuestra salud con el reloj, pasando por la industria de la fabricación. Un freno a esta transformación es la complejidad de los sistemas de IA usados, lo que a menudo plantea desafíos en términos de transparencia y comprensión de los resultados que ofrecen. En este contexto, se habla de la capacidad de explicación – o “explicabilidad” – de la IA como la capacidad para hacer comprensibles sus decisiones y acciones a los usuarios – es lo que se conoce como IA explicable, o XAI por sus siglas en inglés; algo que es crucial para generar confianza y asegurar una adopción responsable de la tecnología.
Explicabilidad de la IA; capacidad para hacer comprensibles sus decisiones y acciones a los usuarios.
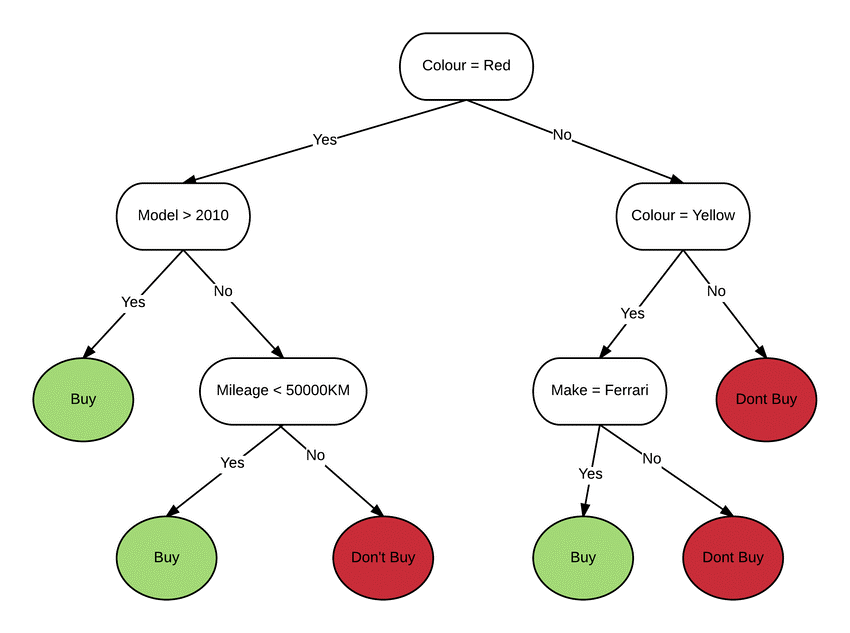
En la actualidad, se trabaja en un amplio abanico de soluciones tecnológicas para mejorar la explicabilidad de los algoritmos de IA. Una de las principales estrategias incluye la creación de modelos intrínsecamente explicables (ante hoc). Estos modelos, como por ejemplo los árboles de decisión y las reglas de asociación, están diseñados para ser transparentes y comprensibles por naturaleza. Su estructura lógica permite a los usuarios seguir fácilmente el razonamiento detrás de las decisiones. Las herramientas de visualización de explicaciones son clave, ya que representan gráficamente el proceso de toma de decisiones del modelo, facilitando su comprensión por parte de los usuarios. Éstas pueden incluir desde cuadros de mando dedicados hasta gafas de realidad aumentada, pasando por explicaciones en lenguaje natural (por voz o texto).
Sistema intrínsecamente explicable: árbol de decisión. Los nodos intermedios son condiciones que verifican progresivamente hasta llegar a la respuesta final; la secuencia de condiciones es la explicación.
Explicación en lenguaje natural de un sistema de recomendación de nuevas rutas para hacer ejercicio. Extraida de Xu et al. (2023). XAIR: framework of XAI in augmented reality.
Otra familia de técnicas de explicación comúnmente utilizada es la de los métodos post hoc: éstos consisten en, una vez creado un modelo de IA complejo, procesar y analizar a posteriori el propio modelo resultante para explicar sus resultados. Por ejemplo, algunas de estas técnicas evalúan cuánto contribuye cada variable en la respuesta final del sistema (análisis de sensibilidad). Entre las técnicas de explicabilidad post hoc destaca SHAP (SHapley Additive exPlanations), un método basado en la teoría de juegos cooperativos, que permite extraer coeficientes que determinan la importancia de cada variable de entrada en el resultado final del algoritmo de IA.
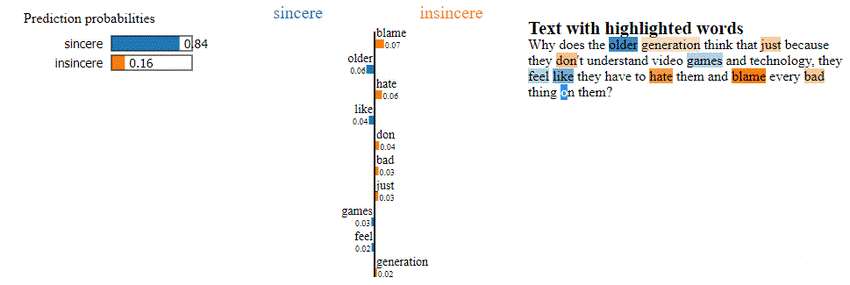
Otras técnicas incluyen la descomposición, que divide el modelo de IA en componentes más simples y más fácilmente explicables, y la destilación en modelos subrogados (knowledge distillation, surrogate models) que aproximan la función del sistema original, pero son más fácilmente comprensibles. Por otro lado, las llamadas “explicaciones locales” consisten en métodos que explican ejemplos individuales (entrada-salida), no el modelo completo. Un ejemplo son las explicaciones proporcionadas por herramientas como LIME (Local Interpretable Model-agnostic Explanations). En el ejemplo de la siguiente figura se explican las palabras más relevantes para determinar por qué el texto se considera ‘sincero’ (con un 84% de fiabilidad) o ‘insincero’ [Linardatos et al. (2020)].
Un enfoque adicional es la integración de entradas de usuarios en el proceso de construcción del modelo, conocido como «Human-in-the-Loop» (HITL). Este enfoque permite a los usuarios interactuar (e.g. etiquetando datos nuevos) y supervisar los algoritmos de IA, ajustando sus decisiones en tiempo real y mejorando así la transparencia del sistema.
En CARTIF, se está trabajando activamente en diferentes proyectos relacionados con IA, como s-X-AIPI para avanzar en la explicabilidad de los sistemas de IA usados para aplicaciones industriales. Un ejemplo significativo de nuestro trabajo son los dashboards (paneles de visualización o cuadros de mando) diseñados para la supervisión y análisis del rendimiento de los procesos de fabricación estudiados en el proyecto. Estos dashboards permiten a los operadores de planta visualizar y entender cómo se está desempeñando el proceso en tiempo real.
Se han creado modelos predictivos y de detección de anomalías para la industria del asfalto que no solo anticipan valores futuros, sino que también detectan situaciones inusuales y explican los factores influyentes en estas predicciones y detecciones. De esta manera, se ayuda a los operarios a tomar decisiones informadas y a entender mejor los resultados generados por los sistemas de IA y como deben actuar.
La explicabilidad en métodos de IA es esencial para su adopción segura y efectiva en todo tipo de sectores: industria, ventas, logística, farmacia, construcción…. En CARTIF, estamos comprometidos con el desarrollo de tecnologías para crear aplicaciones basadas en Inteligencia Artificial que no sólo mejoren los procesos y servicios, sino que también sean transparentes y comprensibles para los usuarios, en definitiva, que sean explicables.
Co-autor
Iñaki Fernández. Doctor en Inteligencia Artificial. Investigador en el área de Salud y Bienestar de CARTIF
El gemelo digital se ha convertido en una de las principales tendencias o «modas» en relación con la digitalización. Prácticamente es un sinónimo de producto, algo que puedes adquirir como un bien más para una empresa. En CARTIF, creemos que el concepto de gemelo digital es un sinónimo del paradigma de la industria 4.0, un enfoque «revolucionario» que ha transformado la forma en que concebimos y gestionamos los procesos industriales.
El término «gemelo digital» fue acuñado porJohn Vickers de la NASA en 2010, pero su predecesor, el ciclo de vida de un producto, fue introducido por Michael Grieves en 2002. Esta filosofía se centraba en gestionar un producto a lo largo de su vida, desde su creación hasta su eliminación. En esencia, el producto físico genera datos que alimentan un espacio virtual, proporcionando información esencial para la toma de decisiones y la optimización del objeto físico.
Una definición de gemelo digital podría ser: «representación digital precisa y completa de objetos físicos, procesos o sistemas con datos en tiempo real y características físicas, comportamientos y relaciones«.
Una pregunta clave es ¿por qué necesitamos gemelos digitales? o ¿cuál es su utilidad? Estas representaciones digitales precisas y en tiempo real ofrecen una serie de ventajas:
Recopilación y análisis de datos para obtener información valiosa y generar conocimiento, lo que impulsa la eficiencia y la toma de decisiones informadas.
Simulación precisa y dinámica del comportamiento de objetos físicos, lo que posibilita pruebas y experimentos virtuales antes de implementar cambios, como inversiones costosas, en el mundo real.
Reducción de costos y riesgos minimizando estos últimos y acelerando la innovación den una amplia gama de sectores, desde la manufactura hasta la atención médica.
Actualización en tiempo real de forma constante a medida que se recopilan nuevos datos del objeto físico, lo que garantiza su validez a lo largo de su ciclo de vida.
Al igual que las revoluciones industriales anteriores, la industria 4.0 ha transformado la forma en que trabajamos. Esta cuarta revolución se centra en la interconexión de sistemas y procesos para lograr una mayor eficiencia en toda la cadena de valor. La fábrica ya no es una entidad aislada, sino un nodo en una red global de producción.
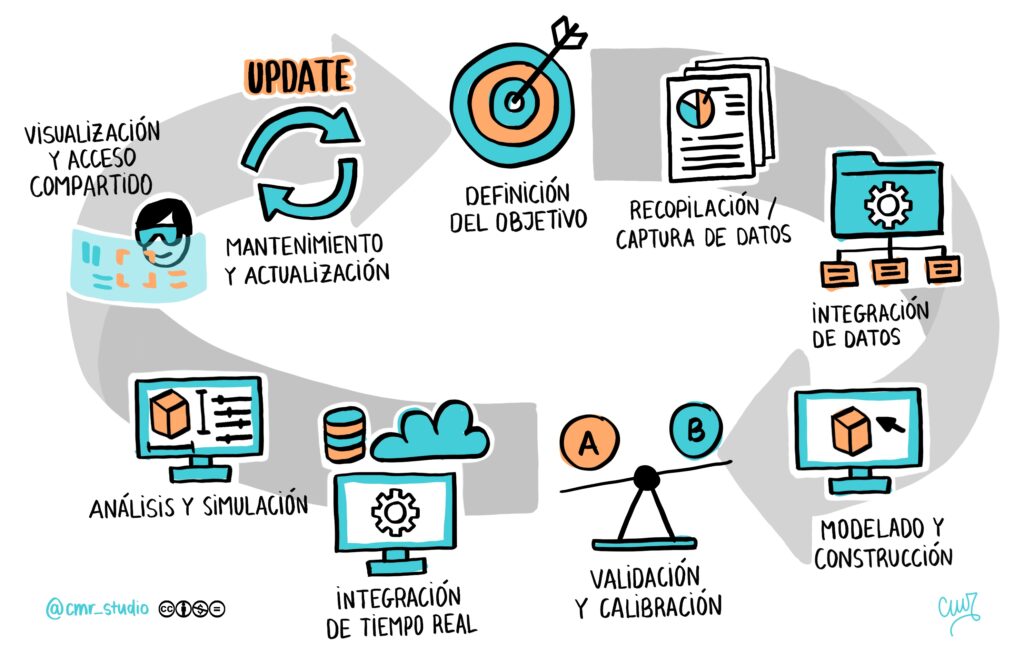
Para crear un gemelo digital efectivo, seguimos una receta sistemática de nueve pasos en CARTIF:
Definición del objetivo: identificamos el objeto físico, proceso o sistema que deseamos replicar y comprendemos claramente su propósito y objetivos.
Recopilación de datos: recolectamos todos los datos relevantes del objeto físico utilizando sensores IoT, registros históricos u otras fuentes de información.
Integración de datos: organizamos y combinamos los datos recopilados en un formato adecuado para su procesamiento y análisis.
Modelado y construcción: utilizamos diferentes tecnologías de simulación y modelado para crear una representación digital precisa del objeto físico.
Validación y calibración: verificamos y ajustamos el modelo del gemelo digital utilizando datos de referencia y pruebas comparativas con el objeto físico real.
Integración en tiempo real: establecemos una conexión en tiempo real entre el gemelo digital y los sensores IoT del objeto físico para recopilar datos en tiempo real.
Análisis y simulación: utilizamos el gemelo digital para realizar análisis, simulaciones y pruebas virtuales del objeto físico.
Visualización y acceso compartido: proporcionamos interfaces virtuales y herramientas de acceso compartido para que los usuarios interactúen con el gemelo digital.
Mantenimiento y actualización: mantenemos el gemelo digital actualizado mediante una recopilación de datos en tiempo real, la calibración periódica y la incorporación de mejoras y actualizaciones.
Así como las revoluciones industriales anteriores requerían tecnologías habilitadoras, la industria 4.0 necesita sus propios habilitadores digitales. Como hemos dicho al principio consideramos al gemelo digital una forma digitalizada del paradigma industria 4.0 porque los habilitadores digitales son fundamentales para la creación de gemelos digitales de forma eficaz. En CARTIF, hemos acumulado casi 30 años de experiencia aplicando estas tecnologías en diversos sectores, desde la industria hasta la salud.
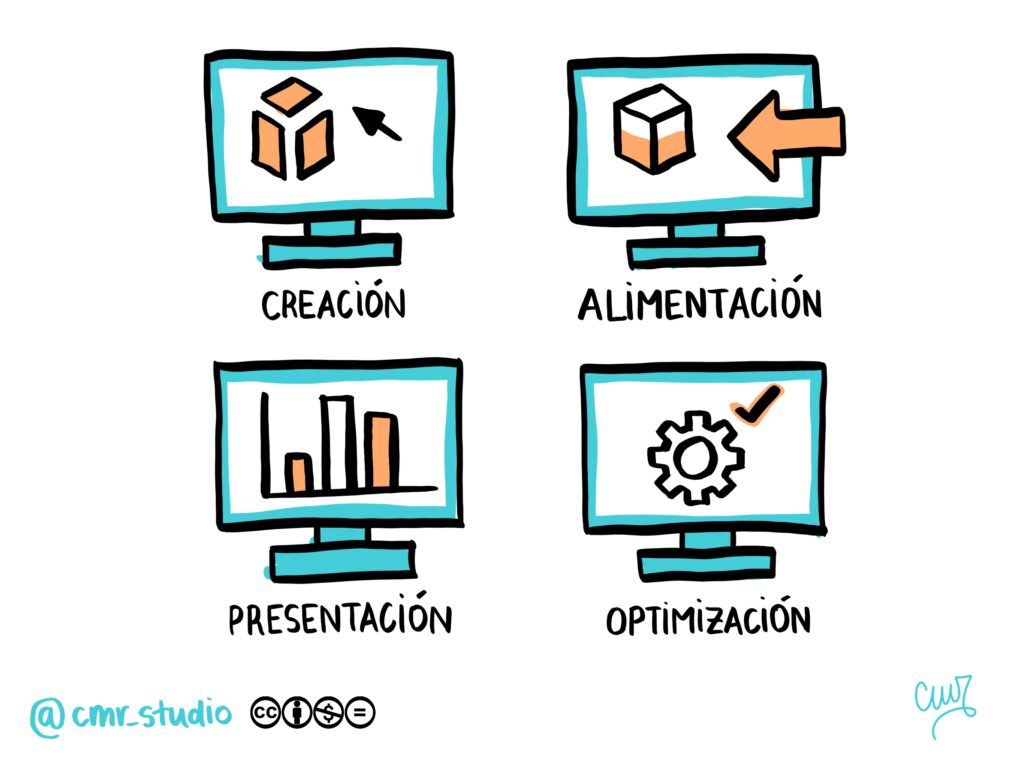
Las tecnologías habilitadores digitales se dividen en cuatro categorías principales:
Tecnologías de creación: estas tecnologías permiten la creación de gemelos digitales mediante ecuaciones físicas, datos, modelado 3D o eventos discretos.
Optimización: la optimización se logra a través de métodos como la programación lineal/no lineal, simulaciones, algoritmos de IA y enfoques heurísticos.
Presentación: la información generada puede presentarse a través de soluciones comerciales, herramientas de código abierto como Grafana o Apache Superset o incluso visualizaciones de realidad aumentada.
A pesar de los avances, el desafío de mantener los gemelos digitales actualizados sigue siendo un área de desarrollo. La actualización automática para reflejar la realidad es un objetivo que requiere una inversión significativa en investigación y desarrollo.
En resumen, los gemelos digitales son el corazón de la industria 4.0, impulsando la eficiencia y la toma de decisiones informadas. En CARTIF, estamos comprometidos a seguir liderando el camino en este emocionante campo, ayudando a diversas industrias a abrazar el futuro digital.
El denominador común en resolución de problemas mediante la inteligencia artificial es la necesidad de datos reales y de buena calidad disponibles para avanzar en los diferentes procedimientos necesarios para crear y entrenar unos modelos adecuados. La investigación práctica en IA a menudo carece de conjuntos de datos disponibles y fiables para que los profesionales puedan probar diferentes algoritmos de inteligencia artificial para la resolución de problemas.
En algunos campos de investigación industrial como el mantenimiento predictivo esta falta de datos es particularmente desafiante, ya que muchos investigadores no tienen acceso a equipos industriales reales o no hay conjuntos de datos disponibles que representen un contenido rico en información en los diferentes tipos de fallos que se puedan presentar en el equipo a analizar. Además de eso, los conjuntos de datos disponibles están claramente desequilibrados desde el punto de vista estadístico, ya que la norma para las máquinas es que funcionen correctamente y solo aparezcan pocos ejemplos de fallas durante su vida útil.
Es muy importante desde el punto de vista de la investigación en IA la disponibilidad de fuentes de datos fiables e interesantes que nos puedan proporcionar gran cantidad de ejemplos para probar diferentes algoritmos de procesamientos de señales e introducir a estudiantes e investigadores en aplicaciones prácticas como el procesamiento de señales, la clasificación o la predicción.
La situación soñada para los investigadores y desarrolladores de soluciones de inteligencia artificial, es que todo el mundo, en la medida de lo posible, comparta datos, pero compartir datos no puede verse solo como una forma de ayudar a otras personas, compartir los datos de investigación puede traer muchas ventajas al donante de estos datos:
Es parte de las buenas prácticas en datos y ciencia abierta, al hacer que los datos sean accesibles junto con los artículos científicos generados.
Reducir el fraude académico y evitar la publicación de estudios basados en datos falsos.
Validar resultados. Cualquiera puede cometer un error, si compartimos los datos que utilizamos, otros investigadores podrían replicar nuestro trabajo y detectar cualquier error potencial.
Más avances científicos. Esto es especialmente cierto en las ciencias sociales y de la salud, donde el intercambio de datos permitiría, por ejemplo, más estudios en el cerebro humano como la enfermedad de Alzheimer y muchos otros.
Mejores herramientas para la docencia basadas en el análisis de casos reales.
Dar mayor relevancia a nuestros trabajos. Diferentes estudios revelan que los trabajos científicos que ponen los datos a disposición en un repositorio público tienen más probabilidades de recibir más referencias que estudios similares para los cuales los datos no están disponibles.
A nivel europeo, la Comisión Europea ha lanzado el Open Research Europe, un programa de publicación científica, para los beneficiarios de proyectos Horizonte 2020 y Horizonte Europa con un servicio para publicar sus resultados en pleno cumplimiento de las políticas de acceso abierto de la Comisión. El servicio proporciona un lugar fácil y de alta calidad revisado por pares para publicar sus resultados en acceso abierto, sin costo para ellos. Otra parte interesante del servicio de esta iniciativa de investigación abierta es Zenodo, un repositorio abierto para cargar los resultados de su investigación (conjuntos de datos, algoritmos, videos,…). Además de las pautas de publicación de investigación abierta, también están disponibles pautas de datos que también se adhieren a los principios F.A.I.R en relación con una serie de repositorios fiables como Zenodo con los que la comisión europea nos obliga a cumplir.
Los principios F.A.I.R a seguir para la publicación de datos significan que los datos y metadatos que los definen deben ser:
Findables (Encontrable): a los (meta)datos se les asigna un identificador global, único y duradero.
Accesibles: los (meta)datos se pueden recuperar por su identificador utilizando un protocolo de comunicaciones estandarizado.
Interoperables: los (meta)datos utilizan un lenguaje formal, accesible, compartido y ampliamente aplicable para representar el conocimiento.
Reutilizables: los meta(datos) se describen de una forma rica, con una serie de atributos precisos, variados y relevantes.
Además, desde el punto de vista gubernamental de la Comisión Europea, tanto la Estrategia Europea de Datos como la política de Gobernanza de Datos son iniciativas poderosas centradas en la implementación de espacios de datos europeos, entre los cuales la Comisión propone la creación de un espacio de datos industrial (fabricación) europeo específico para aprovechar la fuerte base industrial europea y mejorar su competitividad.
Como investigadores de CARTIF, estamos comprometidos a promover la ciencia abierta con nuestros proyectos de investigación. Por ejemplo, en el proyecto CAPRI tiene disponible su propio repositorio Zenodo, donde periódicamente subimos resultados de las soluciones que estamos desarrollando para la industria de procesos, como sensores cognitivos o algoritmos de control cognitivo. Os invitamos a visitar el repositorio y echar un vistazo a más de 40 conjuntos de datos, códigos fuente o vídeos que ya hemos compartido.
Los investigadores cada vez nos enfrentamos más ante situaciones de «digitalizar» algo no digitalizado anteriormente, temperaturas, presiones, consumos energéticos, etc… para estos casos buscamos un sistema de medida o un sensor en un catálogo comercial: una sonda de temperatura, un presostato, una pinza amperimétrica para medir una corriente eléctrica,etc.
En ocasiones, nos vemos en la necesidad de medir «algo» para lo que no se encuentran sensores comerciales. Esto puede ser debido a que no son métricas habituales y no hay suficiente mercado para ese tipo de sensores o directamente, no existen soluciones técnicas comerciales disponibles por diferentes razones. Por ejemplo, puede ser necesario medir características como la humedad de corrientes de materias sólidas, o características únicamente medibles en un laboratorio de control de calidad de forma indirecta y que necesitan un tiempo elevado de experimentación.
También, en ocasiones, se requiere medir características en ambientes de gran dureza por altas temperaturas, como pueden ser los hornos de fundición, o ambientes con mucho polvo que saturan cualquier sistema convencional de medida y en algunas ocasiones puede ser necesario evaluar una cualidad que no se distribuye de forma uniforme (p.ej. cantidad de grasa en una pieza de carne, presencia de impurezas). Otro factor a tener en cuenta, no siempre es posible instalar un sensor sin interferir en el propio proceso de fabricación del material que deseamos medir, o la única forma es tomar una muestra para realizar su análisis fuera de línea y obtener un valor o característica un tiempo después, pero nunca en tiempo real.
En estas situaciones, se necesita recurrir a soluciones a medida que denominamos sensores inteligentes o sensores cognitivos. Además de llamarles así para que parezcan algo exótico o cool, son soluciones que necesitan usar una serie de sensores «convencionales» junto con programas y algoritmos, por ejemplo, de inteligencia artificial, que procesen las medidas devueltas por estos sensores comerciales para tratar de dar una estimación lo más precisa posible de la cualidad que deseamos medir.
Actualmente nos encontramos desarrollando este tipo de sensores inteligentes para diferentes industrias de proceso como la fabricación de asfalto, barras de acero o medicamentos (p.ej. píldoras) en el marco del proyecto europeo CAPRI.
Por ejemplo, en la fabricación de asfalto es necesario secar arenas de diferentes tamaños antes de mezclarse con el betún. Durante el proceso de secado en continuo de estas arenas, el tamaño más fino de arena, denominadofiller, se «desprende» en forma de polvo de árido de tamaño más grande y es necesario aspirar este polvo de forma industrial usando lo que se denomina filtro de mangas. Hoy en día, el secado y la aspiración de filler se realiza de forma que se asegura que todo el filler es extraído. El inconveniente de este proceso, es que, en realidad es necesario añadir filler adicional al mezclar las arenas secadas con el betún, pues es necesario en la mezcla, porque el fillermejora la cohesión de la mezcla rellenando huecos entre los granos de arena. Todo este secado y aspiración completo del filler supone un gasto energético que para tratar de minimizar sería necesario poseer una medida del mismo presente en la mezcla de arenas. Actualmente, esta medida se obtiene de forma puntual a través de un análisis granulométrico en laboratorio con una muestra de material antes de secar.
Dentro del proyecto CAPRI estamos trabajando en la compleja tarea de poder medir el flujo de filler aspirado durante el secado. No se encuentran en el mercado sensores garantizados para medir una gran concentración de polvo (200.000 mg/m3) en suspensión a temperatura elevada (150-200ºC).
Llevar a cabo el desarrollo de este tipo de sensores requiere realizar diferentes pruebas en laboratorio, bajo condiciones controladas que permitan verificar la factibilidad de dicha solución y posteriormente, también en condiciones de laboratorio, realizar unos ensayos calibrados que permitan asegurar que es posible estimar el flujo verdadero de filler aspirado en el proceso de secado de las arenas. El proyecto CAPRI ha completado con éxito las pruebas de este sensor y de otro pertenecientes a la fabricación de barras de acero y píldoras farmacéuticas.
El proyecto en su compromiso con la iniciativa de ciencia abierta impulsada por la Comisión Europea, ha publicado en su canal de Zenodo, diferentes resultados de estas pruebas de laboratorio que nos permiten corroborar el éxito preliminar de dichos sensores a falta de su validación y prueba en las zonas productivas de los socios colaboradores del proyecto. En un futuro próximo estaremos en condiciones de compartir los resultados del funcionamiento industrial de este y otros sensores desarrollados del proyecto.
Co-Autora
Cristina Vega Martínez. Ingeniera Industrial. Coordinadora del proyecto CAPRI H2020
El impacto de la Inteligencia Artificial (IA) es altamente reconocido como uno de los motores clave de la revolución industrial digital junto con los datos y la robótica 1 2. Para aumentar el desarrollo de una IA que sea factible práctica y económicamente en los sectores industriales, necesitamos aplicaciones de IA con interfaces más simples, que no requieran una mano de obra altamente cualificada. Estas aplicaciones de IA deben tener una vida útil más larga y que requiera un mantenimiento menos especializado (por ejemplo, para el etiquetado de datos, entrenamiento, validación…)
Lograr una implementación efectiva de tecnologías de IA confiablesdentro de la industria de proceso requiere una comprensión coherente de cómo estas diferentes tecnologías se complementan e interactúan entre sí en el contexto de los requisitos específicos del dominio que requieren los sectores industriales3.Las industria de proceso deben aprovechar el potencial de la innovación basada en IA, dentro del impulso de la transformación digital, como facilitador clave para alcanzar los objetivos del Green Deal y la esperada transición verde y digital necesaria para una evolución completa hacia la economía circular.
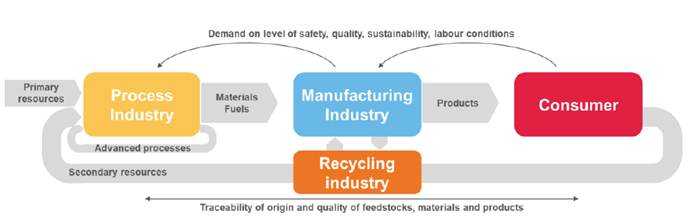
Uno de los retos más importantes para el desarrollo de soluciones innovadoras en la industria de proceso es la complejidad, inestabilidad y imprevisibilidad de sus procesos y el impacto en sus cadenas de valor. Estas soluciones normalmente requieren: funcionar en condiciones adversas, bajo cambios en los valores de los parámetros del proceso, falta de monitoreo/medición consistente de algunos parámetros importantes para analizar el comportamiento del proceso y que son difíciles de medir en tiempo real. A veces, dichos parámetros solo están disponibles a través de análisis de control de calidad en laboratorios que son los responsables de vigilar la trazabilidad del origen y calidad de materias primas, materiales y productos.
Para las aplicaciones basadas en IA, estas restricciones son más críticas, ya que la IA requiere (generalmente) una cantidad considerable de datos de alta calidad para asegurar el rendimiento del proceso de aprendizaje (en términos de precisión y eficiencia). Además, obtener datos de alta calidad, generalmente requiere una participación intensiva de expertos humanos para curar (o incluso crear) datos en un proceso que requiere mucho tiempo. Asimismo, un proceso de aprendizaje supervisado requiere el etiquetado/clasificación de ejemplos de entrenamiento por parte de expertos en el dominio, lo que hace que una solución de IA pueda no ser rentable.
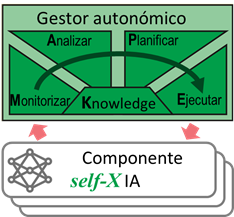
Minimizar (tanto como sea posible) la participación humana en el ciclo de creación de la IA implica algunos cambios fundamentales en la organización de su ciclo de vida, especialmente desde el punto de vista de lograr una IA más autónoma, lo que conduce al concepto de self-X-AI4. Para lograr tal comportamiento autónomo para cualquier tipo de aplicación, generalmente se necesita dotar de habilidades avanzadas (denominadas self-X en inglés y traducidas como auto-X) como las propuestas para la computación autonómica (AC, del inglés Autonomic Computing)5:
Habilidades self-X de computación autonómica
Auto-Configuración: (para facilitar la integración de nuevos sistemas de adaptación al cambio)
Auto-Optimización: (control automático de recursos para un funcionamiento óptimo)
Auto-Recuperación: (detección, diagnóstico y reparación para corrección de errores)
Auto-Protección: (identificación y protección de ataques de una manera proactiva)
Por lo tanto, el paradigma de la computación autonómica puede ayudar en muchas tareas de IA a través de una gestión adecuada 6 7 . En este escenario, la IA actúa como el sistema de procesamiento inteligente y el gestor autonómico ejecuta continuamente un ciclo de Monitoreo-Análisis-Planificación-Ejecución basado en el conocimiento (MAPE-K) del sistema IA controlado, con el objetivo de desarrollar una aplicación IA auto-mejorada.
De hecho, estas nuevas aplicaciones de (self-X) IA serán, hasta cierto punto, autogestionadas para mejorar su propio rendimiento de forma incremental5. Esto se realizará mediante el ciclo de adaptación, que permita «aprender haciendo» utilizando el modelo MAPE-K y las habilidades self-X propuestas por la computación autonómica. El proceso de mejora debe basarse en la capacidad de auto-optimización continua (por ejemplo, ajuste de hiperparámetros en el aprendizaje automático). Además, en el caso de tener problemas en el funcionamiento de un componente de Inteligencia Artificial, el administrador autonómico debe activar las habilidades de auto-configuración (por ejemplo, elección del método de IA), auto-reparación (por ejemplo, detección de desviación del modelo entrenado) y auto-protección (por ejemplo, generar datos artificiales para mejorar los modelos entrenados) según sea necesario, basado en el conocimiento del sistema IA.
En tan solo unas semanas, CARTIF iniciará un proyecto con la ayuda de otras organizaciones expertas en IA y empresas líderes de varios sectores de la industria de proceso Europea para abordar estos desafíos y cerrar la brecha entre la IA y la automatización. El proyecto propone un enfoque novedoso para actualizar de forma continua aplicaciones de IA con una mínima intervención de expertos, a partir de una integración de datos para IA, y proporcionando capacidades de computación autonómica (self-X). La idea principal es permitir la actualización continua de las aplicaciones de IA mediante la integración de datos industriales del mundo físico con una intervención humana reducida.
Os informaremos en futuros posts de los avances que realizaremos con esta nueva generación de aplicaciones IA auto-mejoradas para la industria.