
El impacto de la Inteligencia Artificial (IA) es altamente reconocido como uno de los motores clave de la revolución industrial digital junto con los datos y la robótica 1 2. Para aumentar el desarrollo de una IA que sea factible práctica y económicamente en los sectores industriales, necesitamos aplicaciones de IA con interfaces más simples, que no requieran una mano de obra altamente cualificada. Estas aplicaciones de IA deben tener una vida útil más larga y que requiera un mantenimiento menos especializado (por ejemplo, para el etiquetado de datos, entrenamiento, validación…)
Lograr una implementación efectiva de tecnologías de IA confiables dentro de la industria de proceso requiere una comprensión coherente de cómo estas diferentes tecnologías se complementan e interactúan entre sí en el contexto de los requisitos específicos del dominio que requieren los sectores industriales3.Las industria de proceso deben aprovechar el potencial de la innovación basada en IA, dentro del impulso de la transformación digital, como facilitador clave para alcanzar los objetivos del Green Deal y la esperada transición verde y digital necesaria para una evolución completa hacia la economía circular.
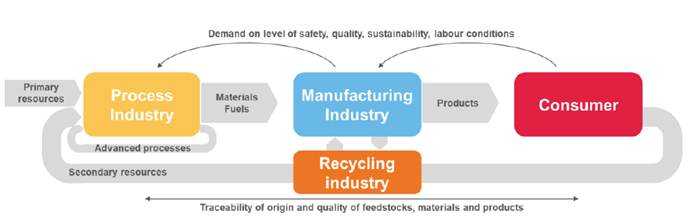
Uno de los retos más importantes para el desarrollo de soluciones innovadoras en la industria de proceso es la complejidad, inestabilidad y imprevisibilidad de sus procesos y el impacto en sus cadenas de valor. Estas soluciones normalmente requieren: funcionar en condiciones adversas, bajo cambios en los valores de los parámetros del proceso, falta de monitoreo/medición consistente de algunos parámetros importantes para analizar el comportamiento del proceso y que son difíciles de medir en tiempo real. A veces, dichos parámetros solo están disponibles a través de análisis de control de calidad en laboratorios que son los responsables de vigilar la trazabilidad del origen y calidad de materias primas, materiales y productos.
Para las aplicaciones basadas en IA, estas restricciones son más críticas, ya que la IA requiere (generalmente) una cantidad considerable de datos de alta calidad para asegurar el rendimiento del proceso de aprendizaje (en términos de precisión y eficiencia). Además, obtener datos de alta calidad, generalmente requiere una participación intensiva de expertos humanos para curar (o incluso crear) datos en un proceso que requiere mucho tiempo. Asimismo, un proceso de aprendizaje supervisado requiere el etiquetado/clasificación de ejemplos de entrenamiento por parte de expertos en el dominio, lo que hace que una solución de IA pueda no ser rentable.
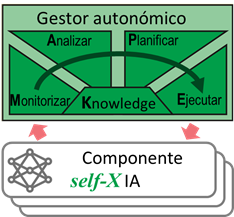
Minimizar (tanto como sea posible) la participación humana en el ciclo de creación de la IA implica algunos cambios fundamentales en la organización de su ciclo de vida, especialmente desde el punto de vista de lograr una IA más autónoma, lo que conduce al concepto de self-X-AI4. Para lograr tal comportamiento autónomo para cualquier tipo de aplicación, generalmente se necesita dotar de habilidades avanzadas (denominadas self-X en inglés y traducidas como auto-X) como las propuestas para la computación autonómica (AC, del inglés Autonomic Computing)5:
Habilidades self-X de computación autonómica
| Auto-Configuración: (para facilitar la integración de nuevos sistemas de adaptación al cambio) |
| Auto-Optimización: (control automático de recursos para un funcionamiento óptimo) |
| Auto-Recuperación: (detección, diagnóstico y reparación para corrección de errores) |
| Auto-Protección: (identificación y protección de ataques de una manera proactiva) |
Por lo tanto, el paradigma de la computación autonómica puede ayudar en muchas tareas de IA a través de una gestión adecuada 6 7 . En este escenario, la IA actúa como el sistema de procesamiento inteligente y el gestor autonómico ejecuta continuamente un ciclo de Monitoreo-Análisis-Planificación-Ejecución basado en el conocimiento (MAPE-K) del sistema IA controlado, con el objetivo de desarrollar una aplicación IA auto-mejorada.
De hecho, estas nuevas aplicaciones de (self-X) IA serán, hasta cierto punto, autogestionadas para mejorar su propio rendimiento de forma incremental5. Esto se realizará mediante el ciclo de adaptación, que permita «aprender haciendo» utilizando el modelo MAPE-K y las habilidades self-X propuestas por la computación autonómica. El proceso de mejora debe basarse en la capacidad de auto-optimización continua (por ejemplo, ajuste de hiperparámetros en el aprendizaje automático). Además, en el caso de tener problemas en el funcionamiento de un componente de Inteligencia Artificial, el administrador autonómico debe activar las habilidades de auto-configuración (por ejemplo, elección del método de IA), auto-reparación (por ejemplo, detección de desviación del modelo entrenado) y auto-protección (por ejemplo, generar datos artificiales para mejorar los modelos entrenados) según sea necesario, basado en el conocimiento del sistema IA.
En tan solo unas semanas, CARTIF iniciará un proyecto con la ayuda de otras organizaciones expertas en IA y empresas líderes de varios sectores de la industria de proceso Europea para abordar estos desafíos y cerrar la brecha entre la IA y la automatización. El proyecto propone un enfoque novedoso para actualizar de forma continua aplicaciones de IA con una mínima intervención de expertos, a partir de una integración de datos para IA, y proporcionando capacidades de computación autonómica (self-X). La idea principal es permitir la actualización continua de las aplicaciones de IA mediante la integración de datos industriales del mundo físico con una intervención humana reducida.
Os informaremos en futuros posts de los avances que realizaremos con esta nueva generación de aplicaciones IA auto-mejoradas para la industria.
1 Processes4Planet, SRIA 2050 advanced working version
2 EFFRA, The manufacturing partnership in Horizon Europe Strategic Research and Innovation Agenda.
3 https://www.spire2030.eu/news/new/artificial-intelligence-eu-process-industry-view-spire-cppp
4 Alahakoon, D., et al. Self-Building Artificial Intelligence and Machine Learning to Empower Big Data Analytics in Smart Cities. Inf Syst Front (2020). https://link.springer.com/article/10.1007/s10796-020-10056-x
5 Sundeep Teki, Aug 2021, https://neptune.ai/blog/improving-machine-learning-deep-learning-models
6 Curry, E; Grace, P (2008), “Flexible Self-Management Using the Model–View–Controller Pattern”, doi:10.1109/MS.2008.60
7 Stefan Poslad, Ubiquitous Computing: Smart Devices, Environments and Interactions, ISBN: 978-0-470-03560-3

- Tras el telón: Inteligencia Artificial Explicable - 12 julio 2024
- Gemelo Digital: la Industria 4.0 en su forma digitalizada - 9 octubre 2023
- Inteligencia Artificial, una inteligencia que necesita datos nada artificiales - 16 diciembre 2022