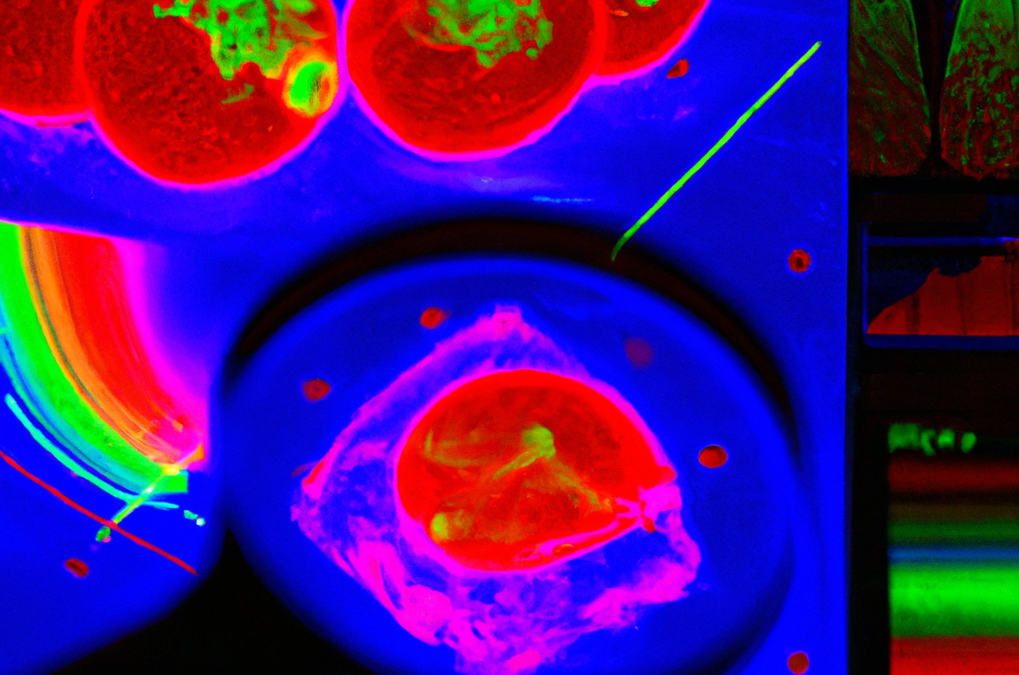
En este post, me gustaría hablar de los dispositivos con capacidad de adquisición de imágenes en el rango espectral de los Terahercios, una tecnología emergente con un gran potencial de implantación en la industria, especialmente en el sector agroalimentario.
En la actualidad, los sistemas de visión artificial utilizados en la industria trabajan con diferentes rangos del espectro electromagnético, como la luz visible, infrarroja, ultravioleta, entre otros, que no son capaces de atravesar la materia. Por lo tanto, estas tecnologías solo pueden examinar las características de la superficie de un producto o envase, pero no pueden proporcionar información del interior.
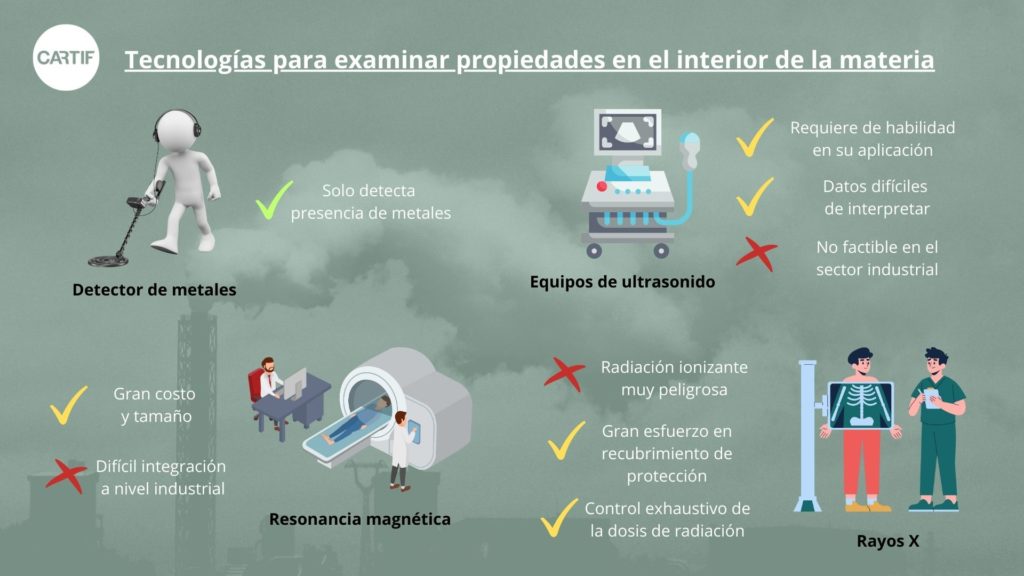
Por el contrario, existen otras tecnologías que sí nos permiten examinar ciertas propiedades en el interior de la materia, como es el caso de los detectores de metales, la resonancia magnética, los ultrasonidos y los rayos X. Los detectores de metales solo tienen capacidad para detectar la presencia de metales. Los equipos de resonancia magnética tienen un alto costo y son de gran tamaño, utilizados básicamente en medicina, siendo prácticamente inviable su integración a nivel industrial. Los equipos de ultrasonido requieren contacto, cierta habilidad en su aplicación y son difíciles de interpretar, por lo que no es factible en el sector industrial. Finalmente, los rayos X son una radiación ionizante muy peligrosa, la cual implica un gran esfuerzo en recubrimientos de protección y un control exhaustivo de la dosis de radiación. Aunque pueden atravesar la materia, los rayos X solo pueden proporcionar información sobre las diferentes partes de un producto que absorben en este rango del espectro electromagnético.
Desde este punto de vista, nos encontramos ante un reto muy importante; investigar en el potencial de nuevas tecnologías con capacidad de inspeccionar, sin peligro y sin contacto, el interior de productos y envases, obteniendo información relevante de las características internas, como pueden ser la calidad, el estado, la presencia o ausencia de elementos en su interior, la homogeneidad, etc.
Estudiando las opciones, la solución puede estar en potenciar la integración en la industria de nuevas tecnologías que trabajen en rangos espectrales no-ionizantes con capacidad de penetrar la materia, como es el caso del rango espectral del terahercio/microondas cercano.
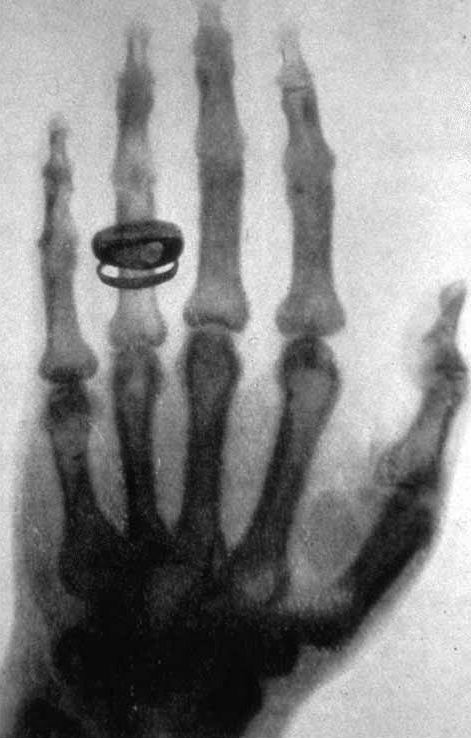
Primera radiografía de la historia. La mano de la mujer de Röngten
En 1985, el profesor Röntgen tomó la primera imagen radiológica en la historia, la mano de su mujer, han pasado 127 años y aún se sigue investigando. En 1995, se captó la primera imagen en el rango del Terahercio, por lo que solo han pasado 27 años desde entonces. Esto muestra el grado de madurez de la tecnología de Terahercios, aún en sus primeras fases de investigación. Esta radiación no es nueva, sabemos que está ahí, pero a día de hoy es muy difícil generarla y detectarla. Los principales trabajos de investigación se han centrado en mejorar la forma de emitir y captar esta radiación de una forma coherente, a partir de equipos desarrollados en el laboratorio.
En los últimos años las cosas han cambiado, se han obtenido nuevos sensores ópticos y nuevas fuentes de terahercios con una capacidad de industrialización muy alta, lo que abre las puertas de la industria a esta tecnología. Ahora queda una labor muy importante de investigación para ver los alcances de esta tecnología en los diferentes ámbitos de la industria.
Desde CARTIF se está apostando por esta tecnología y en la actualidad se trabaja en el desarrollo del proyecto de investigación industrial AGROVIS, «Computación VIsual inteligente para productos/procesos del sector AGROalimentario», un proyecto financiado por la Junta de Castilla y León, enmarcado en el campo de la visión por computador (habilitador digital de la industria 4.0) asociada al sector agroalimentario, donde uno de los principales objetivos es explorar las distintas posibilidades para inspeccionar automáticamente el interior de productos agroalimentarios de forma segura.
Elicitar (del latín elicitus, «inducido» y elicere, «atrapar») es un término usado en psicología asociado al traspaso de información de forma fluida de un ser humano a otro por medio del lenguaje.
La elicitación del conocimiento aplicado en la industria es un proceso mediante el cual se recoge y registra información y conocimiento valioso de expertos o personas con experiencia en una determinada área en la organización. Es una técnica utilizada para identificar, extraer y documentar el conocimiento tácito (implícito) que se encuentra en la mente de los individuos o en los procesos organizacionales. Es una forma de recopilar y registrar el conocimiento existente y no disponible en la documentación formal, utilizado en diferentes ámbitos como la gestión del conocimiento, la ingeniería, o en el ámbito de negocios, entre otros. La elicitación de conocimiento puede usarse dentro del ámbito de la ingeniería para optimizar procesos industriales, crear sistemas expertos, para aplicaciones basadas en IA, etc.
Por ejemplo, si fuera tecnológicamente posible tener acceso a la mente de los trabajadores como plantean en la serie de ficción Severance (en español Separación) donde una siniestra corporación de biotecnología, Lumon Industries, utiliza un procedimiento médico de separación de recuerdos laborales de los no laborales, este conocimiento podría quedar registrado y disponible para ser utilizado, pero también está claro que esta premisa plantearía preocupaciones éticas y legales importantes en este momento de la historia, no sabemos en un futuro cercano.
El objetivo de la elicitación es obtener información precisa y relevante para ayudar en la toma de decisiones, mejorar la eficiencia y apoyar la capacitación y el desarrollo. Con esta información se elaboran unas reglas óptimas de actuación de los expertos que sirven de entrada principal para los controles que pueden ser programados en un proceso productivo.
La elicitación del conocimiento es importante por varias razones. En primer lugar (1), permite a las organizaciones documentar el conocimiento existente de los expertos en un área específica. Esto puede ayudar a evitar la re-invención de la rueda y mejorar la eficiencia en la toma de decisiones. En segundo lugar (2), la elicitación del conocimiento también puede ayudar a identificar las brechas en el conocimiento de una organización, lo que permite a las mismas tomar medidas de antemano. En tercer lugar (3), este proceso de elicitación puede ayudar a fomentar la colaboración y el intercambio de conocimientos entre los empleados de una organización.
La metodología para elicitación del conocimiento requiere una serie de pasos a seguir:
Análisis de requisitos: identificar el enfoque de los sistemas basados en conocimiento.
Modelado conceptual: creación de una base de terminología utilizada, definición de interrelaciones y restricciones.
Construcción de una base de conocimiento: reglas, hechos, casos o restricciones.
Operación y validación: Operar usando mecanismos de razonamiento automatizado.
Regresar al análisis de requerimientos si es necesario o continuar en el proceso.
Mejora y mantenimiento: ampliando conocimiento el sistema evoluciona, repetir a lo largo de la vida del sistema.
Posteriormente, es necesario realizar un análisis del conocimiento recogido, determinar que información es relevante y cual no lo es tanto, para que el resultado sea conocimiento de alta calidad. Un punto crítico de la elicitación es la disponibilidad de los expertos en el dominio involucrado, su contribución debería estar disponible a través de todas las etapas del proceso para garantizar buenos resultados.
Para un desarrollo correcto del proceso de elicitación es necesario contar con los siguientes elementos:
Expertos
Los expertos en el proceso pueden tener diferentes puntos de vista de un mismo asunto, debido a su experiencia, conocimientos e incluso aspectos más subjetivos como mentalidad, manera de enfocar las dificultades, retos, etc. Se debe considerar expertos especialistas en diferentes etapas, en diferentes infraestructuras, equipos, productos, etc.
Las barreras que pueden aparecer en este tipo de intercambio de información es que suelen contener ideas complejas y asociaciones, difíciles de comunicar de una manera sencilla, con detalle y organización, el uso del mismo lenguaje, como conceptos o vocabulario específico.
Las herramientas para la elicitación del conocimiento ayudan a los usuarios o expertos, a documentar sus propias necesidades al operar los procesos productivos mediante entrevistas presenciales u online, reuniones en grupo, estudios in situ, etc.
Entrevistas
Para adquirir conocimiento experto la mejor técnica es llevar a cabo una serie de entrevistas personales. Algunos de los inconvenientes de llevarlas a cabo son: la distancia, el tiempo requerido y el personal necesario para involucrar en este proceso. Por lo que los cuestionarios en papel u online, pueden ser una opción válida, que ahorra tiempo y costes y se facilita que estén presentes en le cuestionario todas las secciones, facilitando la comparativa y la evaluación de los resultados.
Las características para un buen diseño del cuestionario implican: (1) determinar la información relevante, (2) una buena estructuración con diferentes secciones ordenadas por temáticas, (3) ordenar cuestiones de más general a más en detalle en cada sección, focalizando en la idea de esa sección, con ello se evita la introducción de sesgos, malentendidos o errores, (4) realizar el diseño con un experto de dominio para asegurar que las cuestiones son suficientemente comprensibles para facilitar la respuesta.
Resultados
Los resultados esperados son las acciones a realizar por los operadoresde las líneas cuando se producen desviaciones de los parámetros. Estas respuestas junto con la información recogida se transforman en reglas óptimas necesarias para programar controles automáticos sobre el proceso, y donde estas reglas son el elemento principal. La obtención de las reglas no es una tarea fácil, se recomienda un proceso iterativo y heurístico en varias fases. Para la validación es necesaria una comparativa de la información recogida en la base de datos con las respuestas de los operadores para verificar las acciones cuando se producen las desviaciones de los parámetros de los valores deseados.
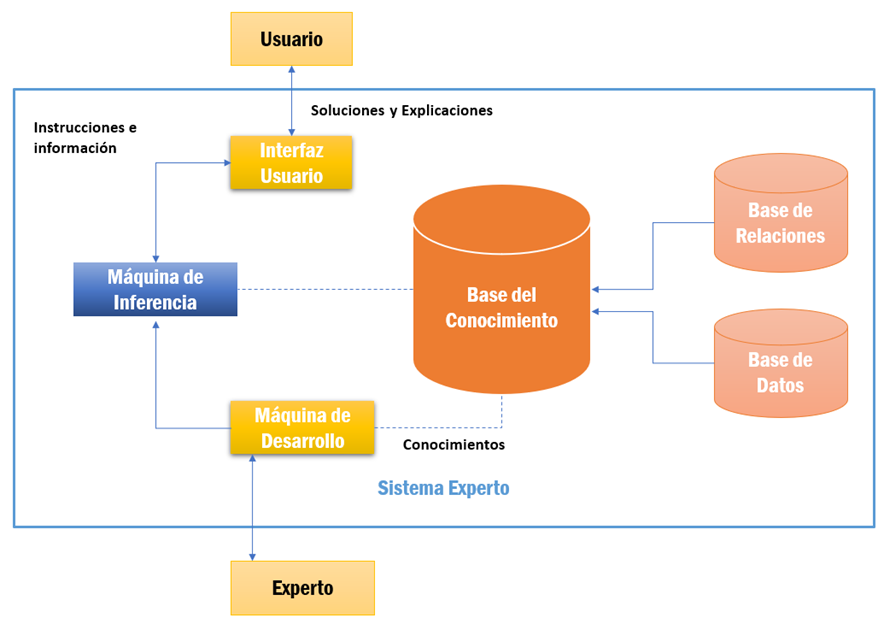
Se puede ver en la siguiente imagen de un sistema experto como estas reglas óptimas o también denominadas reglas if-then forman parte de la base de conocimiento, en concreto de la base de relaciones, que es la parte de un sistema experto que contiene el conocimiento sobre el dominio. En un primer paso, se obtiene el conocimiento del experto y posteriormente se codifica en la base de relaciones como reglas if-then.
Finalmente es cuando se puede utilizar lógica difusa o borrosa para el diseño e implementación de un sistema experto, es la lógica que utiliza expresiones que no son ni totalmente ciertas ni falsas, permite tratar información imprecisa como estatura media o temperatura baja, en términos de conjuntos denominados «borrosos» que se combinan en reglas para definir acciones: p.e. «si la temperatura es alta entonces enfriar mucho». Este tipo de lógica es necesaria si se quiere aproximar mejor a la forma de pensar de un experto, cuyo razonamiento no se basa en valores verdadero y falso típico de la lógica clásica, sino que requiere un manejo amplio de ambigüedades e incertidumbres propias de la psicología humana.
Actualmente en CARTIF la elicitación de conocimiento experto se está utilizando en el proyecto INTELIFER, cuyo principal objetivo es la optimización del proceso y los productos de una línea de fabricación de fertilizantes granulados NPK con apoyo de la inteligencia artificial.
La operación óptima de este tipo de plantas de fertilizantes granulados depende en un alto porcentaje de la habilidad de operadores expertos, pero que, a pesar de sus destrezas y habilidades, no pueden evitar las altas tasas de reciclo, frecuentes inestabilidades y paradas no deseadas, debido principalmente a la naturaleza extremadamente compleja del proceso de granulación siendo un proceso no lineal, acoplado, estocástico, multietapa, multiproducto, multivariable,etc. Por lo que la situación anteriormente expuesta ha supuesto la base científica para la definición del presente proyecto, siendo necesario el desarrollo de actividades de I+D en las cuales, mediante la aplicación de la filosofía de la inteligencia artificial junto con un mayor grado de sensorización y digitalización, se consiga optimizar este tipo de procesos de fabricación.
El denominador común en resolución de problemas mediante la inteligencia artificial es la necesidad de datos reales y de buena calidad disponibles para avanzar en los diferentes procedimientos necesarios para crear y entrenar unos modelos adecuados. La investigación práctica en IA a menudo carece de conjuntos de datos disponibles y fiables para que los profesionales puedan probar diferentes algoritmos de inteligencia artificial para la resolución de problemas.
En algunos campos de investigación industrial como el mantenimiento predictivo esta falta de datos es particularmente desafiante, ya que muchos investigadores no tienen acceso a equipos industriales reales o no hay conjuntos de datos disponibles que representen un contenido rico en información en los diferentes tipos de fallos que se puedan presentar en el equipo a analizar. Además de eso, los conjuntos de datos disponibles están claramente desequilibrados desde el punto de vista estadístico, ya que la norma para las máquinas es que funcionen correctamente y solo aparezcan pocos ejemplos de fallas durante su vida útil.
Es muy importante desde el punto de vista de la investigación en IA la disponibilidad de fuentes de datos fiables e interesantes que nos puedan proporcionar gran cantidad de ejemplos para probar diferentes algoritmos de procesamientos de señales e introducir a estudiantes e investigadores en aplicaciones prácticas como el procesamiento de señales, la clasificación o la predicción.
La situación soñada para los investigadores y desarrolladores de soluciones de inteligencia artificial, es que todo el mundo, en la medida de lo posible, comparta datos, pero compartir datos no puede verse solo como una forma de ayudar a otras personas, compartir los datos de investigación puede traer muchas ventajas al donante de estos datos:
Es parte de las buenas prácticas en datos y ciencia abierta, al hacer que los datos sean accesibles junto con los artículos científicos generados.
Reducir el fraude académico y evitar la publicación de estudios basados en datos falsos.
Validar resultados. Cualquiera puede cometer un error, si compartimos los datos que utilizamos, otros investigadores podrían replicar nuestro trabajo y detectar cualquier error potencial.
Más avances científicos. Esto es especialmente cierto en las ciencias sociales y de la salud, donde el intercambio de datos permitiría, por ejemplo, más estudios en el cerebro humano como la enfermedad de Alzheimer y muchos otros.
Mejores herramientas para la docencia basadas en el análisis de casos reales.
Dar mayor relevancia a nuestros trabajos. Diferentes estudios revelan que los trabajos científicos que ponen los datos a disposición en un repositorio público tienen más probabilidades de recibir más referencias que estudios similares para los cuales los datos no están disponibles.
A nivel europeo, la Comisión Europea ha lanzado el Open Research Europe, un programa de publicación científica, para los beneficiarios de proyectos Horizonte 2020 y Horizonte Europa con un servicio para publicar sus resultados en pleno cumplimiento de las políticas de acceso abierto de la Comisión. El servicio proporciona un lugar fácil y de alta calidad revisado por pares para publicar sus resultados en acceso abierto, sin costo para ellos. Otra parte interesante del servicio de esta iniciativa de investigación abierta es Zenodo, un repositorio abierto para cargar los resultados de su investigación (conjuntos de datos, algoritmos, videos,…). Además de las pautas de publicación de investigación abierta, también están disponibles pautas de datos que también se adhieren a los principios F.A.I.R en relación con una serie de repositorios fiables como Zenodo con los que la comisión europea nos obliga a cumplir.
Los principios F.A.I.R a seguir para la publicación de datos significan que los datos y metadatos que los definen deben ser:
Findables (Encontrable): a los (meta)datos se les asigna un identificador global, único y duradero.
Accesibles: los (meta)datos se pueden recuperar por su identificador utilizando un protocolo de comunicaciones estandarizado.
Interoperables: los (meta)datos utilizan un lenguaje formal, accesible, compartido y ampliamente aplicable para representar el conocimiento.
Reutilizables: los meta(datos) se describen de una forma rica, con una serie de atributos precisos, variados y relevantes.
Además, desde el punto de vista gubernamental de la Comisión Europea, tanto la Estrategia Europea de Datos como la política de Gobernanza de Datos son iniciativas poderosas centradas en la implementación de espacios de datos europeos, entre los cuales la Comisión propone la creación de un espacio de datos industrial (fabricación) europeo específico para aprovechar la fuerte base industrial europea y mejorar su competitividad.
Como investigadores de CARTIF, estamos comprometidos a promover la ciencia abierta con nuestros proyectos de investigación. Por ejemplo, en el proyecto CAPRI tiene disponible su propio repositorio Zenodo, donde periódicamente subimos resultados de las soluciones que estamos desarrollando para la industria de procesos, como sensores cognitivos o algoritmos de control cognitivo. Os invitamos a visitar el repositorio y echar un vistazo a más de 40 conjuntos de datos, códigos fuente o vídeos que ya hemos compartido.
La visión artificial es uno de los habilitadores de la Industria 4.0 con una mayor integración en las líneas de producción, especialmente en el control de calidad de productos y procesos. En los últimos años, se está produciendo una auténtica revolución en este campo con la integración de la Inteligencia Artificial en el procesamiento de imágenes, con un potencial aún por descubrir. A pesar de las limitaciones que presenta la Inteligencia Artificial en cuanto a fiabilidad, se están obteniendo resultados en la industria que antes eran impensables aplicando la visión artificial tradicional.
El propósito de este post no es hablar de las posibilidades de la Inteligencia Artificial, ya que son muchos los blogs que se encargan de esta tarea, el propósito es resaltar el potencial de la visión artificial tradicional cuando se tiene experiencia y se desarrollan buenas ideas.
La visión artificial no es solo un conjunto de algoritmos que se aplican directamente sobre imágenes obtenidas por cámaras de altas prestaciones. Cuando desarrollamos un sistema de visión industrial, lo hacemos para detectar una variedad de defectos o características propias del producto. Nuestra labor es seleccionar la tecnología más adecuada y generar las condiciones óptimas en la escena para poder extraer la información requerida del mundo físico a partir de las imágenes capturadas. Son muchas las variables a considerar en esta tarea: las características de la iluminación empleada en la escena; la posición relativa entre los equipos de adquisición, el sistema de iluminación y el objeto a analizar; las características de la zona de inspección; la configuración y sensibilidad de los sistemas de adquisición, etc.
Como anécdota representativa de la importancia de la experiencia, me gustaría destacar un caso que se nos dio en una factoría de componentes para el automóvil.
La empresa tenía instalado un sistema de visión comercial de altas prestaciones cuyo objetivo era identificar varias piezas en función del color. Después de varios fracasos, se nos pidió ayuda para configurar dichos equipos, pero en lugar de actuar sobre estos dispositivos, trabajamos en cambiar las condiciones de iluminación de la escena y simplemente, dimos la vuelta a los focos y colocamos unos paneles para obtener una iluminación difusa en lugar de una iluminación directa. Con esto se solucionó el problema y la visión alcanzó el nivel de fiabilidad que requería el cliente.
En este post, me gustaría destacar un caso de éxito importante en la industria de la automoción que ha tenido un impacto relevantes en su proceso productivo, este es el sistema de visión SIVAM5 desarrollado por CARTIF e integrado en líneas de embutición en frio de chapa laminada.
Como todos sabemos, la calidad superficial del exterior del vehículo es clave para los usuarios, por lo que las empresas del sector de la automoción tienen que realizar un importante esfuerzo para detectar y corregir la presencia de defectos en la carrocería de sus vehículos. Gran parte de estos defectos se producen en la etapa de estampación, pero considerando la inconsistencia del color de la chapa y la generación de reflejos difusos, en algunos casos estos defectos pasan inadvertidos a la etapa de ensamblaje de la carrocería y posteriormente, a la etapa de pintura, tras la cual se manifiestan notoriamente. Esto implica que un pequeño defecto no detectado a tiempo se traduce en un gran coste para la producción del vehículo .
Para detectar estos defectos en una fase temprana, hemos desarrollado un innovador sistema de visión artificial para detectar las microgrietas y los porosque se generan en el proceso de estampación en frío de chapa laminada. Este es el claro ejemplo de una solución robusta basada en una idea sencilla, «el paso de la luz a través de los poros de la chapa», pero en la que se ha realizado un gran esfuerzo tecnológico para implantar la idea en la línea de producción. Para ello se han combinado diversas tecnologías ópticas y se han desarrollado complejos sistemas mecánicos, lo que ha permitido obtener una solución tecnológica de altas prestaciones, capaz de realizar una inspección exhaustiva de los puntos críticos de las chapas en el 100% de la producción y sin penalizar los breves tiempos de cadencia que caracterizan a las líneas de prensa.
Gracias a su excelente resistencia a vibraciones e impactos, a su gran capacidad de adaptación para la integración de nuevas referencias y a su fiabilidad en la detección de defectos, se ha obtenido una solución robusta, flexible y fiable. Partiendo de una idea sencilla, se ha implantado una solución robusta en el proceso productivo de grandes empresas del sector de la automoción, como Renault y Gestamp, donde lleva operativa sin actualizaciones más de 20 años, funcionando día y noche.
Los investigadores cada vez nos enfrentamos más ante situaciones de «digitalizar» algo no digitalizado anteriormente, temperaturas, presiones, consumos energéticos, etc… para estos casos buscamos un sistema de medida o un sensor en un catálogo comercial: una sonda de temperatura, un presostato, una pinza amperimétrica para medir una corriente eléctrica,etc.
En ocasiones, nos vemos en la necesidad de medir «algo» para lo que no se encuentran sensores comerciales. Esto puede ser debido a que no son métricas habituales y no hay suficiente mercado para ese tipo de sensores o directamente, no existen soluciones técnicas comerciales disponibles por diferentes razones. Por ejemplo, puede ser necesario medir características como la humedad de corrientes de materias sólidas, o características únicamente medibles en un laboratorio de control de calidad de forma indirecta y que necesitan un tiempo elevado de experimentación.
También, en ocasiones, se requiere medir características en ambientes de gran dureza por altas temperaturas, como pueden ser los hornos de fundición, o ambientes con mucho polvo que saturan cualquier sistema convencional de medida y en algunas ocasiones puede ser necesario evaluar una cualidad que no se distribuye de forma uniforme (p.ej. cantidad de grasa en una pieza de carne, presencia de impurezas). Otro factor a tener en cuenta, no siempre es posible instalar un sensor sin interferir en el propio proceso de fabricación del material que deseamos medir, o la única forma es tomar una muestra para realizar su análisis fuera de línea y obtener un valor o característica un tiempo después, pero nunca en tiempo real.
En estas situaciones, se necesita recurrir a soluciones a medida que denominamos sensores inteligentes o sensores cognitivos. Además de llamarles así para que parezcan algo exótico o cool, son soluciones que necesitan usar una serie de sensores «convencionales» junto con programas y algoritmos, por ejemplo, de inteligencia artificial, que procesen las medidas devueltas por estos sensores comerciales para tratar de dar una estimación lo más precisa posible de la cualidad que deseamos medir.
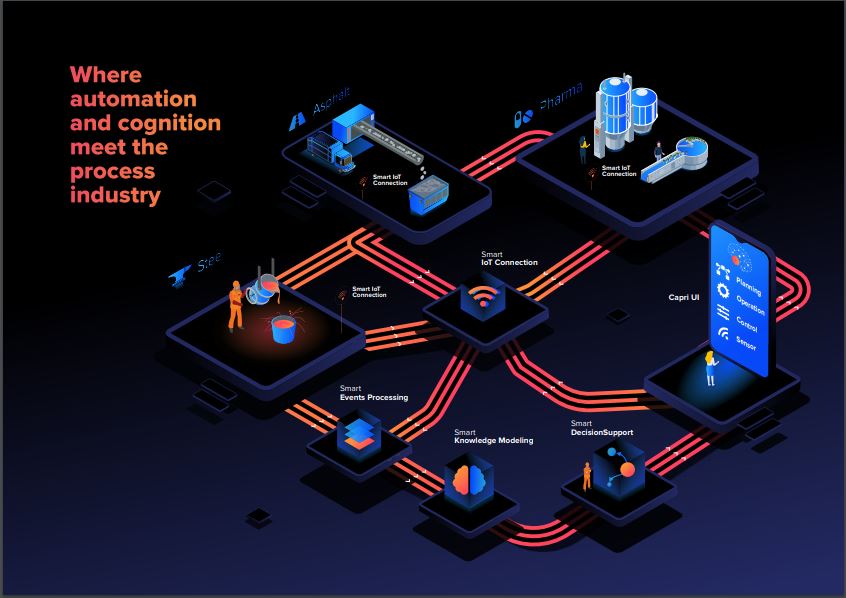
Actualmente nos encontramos desarrollando este tipo de sensores inteligentes para diferentes industrias de proceso como la fabricación de asfalto, barras de acero o medicamentos (p.ej. píldoras) en el marco del proyecto europeo CAPRI.
Por ejemplo, en la fabricación de asfalto es necesario secar arenas de diferentes tamaños antes de mezclarse con el betún. Durante el proceso de secado en continuo de estas arenas, el tamaño más fino de arena, denominadofiller, se «desprende» en forma de polvo de árido de tamaño más grande y es necesario aspirar este polvo de forma industrial usando lo que se denomina filtro de mangas. Hoy en día, el secado y la aspiración de filler se realiza de forma que se asegura que todo el filler es extraído. El inconveniente de este proceso, es que, en realidad es necesario añadir filler adicional al mezclar las arenas secadas con el betún, pues es necesario en la mezcla, porque el fillermejora la cohesión de la mezcla rellenando huecos entre los granos de arena. Todo este secado y aspiración completo del filler supone un gasto energético que para tratar de minimizar sería necesario poseer una medida del mismo presente en la mezcla de arenas. Actualmente, esta medida se obtiene de forma puntual a través de un análisis granulométrico en laboratorio con una muestra de material antes de secar.
Dentro del proyecto CAPRI estamos trabajando en la compleja tarea de poder medir el flujo de filler aspirado durante el secado. No se encuentran en el mercado sensores garantizados para medir una gran concentración de polvo (200.000 mg/m3) en suspensión a temperatura elevada (150-200ºC).
Llevar a cabo el desarrollo de este tipo de sensores requiere realizar diferentes pruebas en laboratorio, bajo condiciones controladas que permitan verificar la factibilidad de dicha solución y posteriormente, también en condiciones de laboratorio, realizar unos ensayos calibrados que permitan asegurar que es posible estimar el flujo verdadero de filler aspirado en el proceso de secado de las arenas. El proyecto CAPRI ha completado con éxito las pruebas de este sensor y de otro pertenecientes a la fabricación de barras de acero y píldoras farmacéuticas.
El proyecto en su compromiso con la iniciativa de ciencia abierta impulsada por la Comisión Europea, ha publicado en su canal de Zenodo, diferentes resultados de estas pruebas de laboratorio que nos permiten corroborar el éxito preliminar de dichos sensores a falta de su validación y prueba en las zonas productivas de los socios colaboradores del proyecto. En un futuro próximo estaremos en condiciones de compartir los resultados del funcionamiento industrial de este y otros sensores desarrollados del proyecto.
Co-Autora
Cristina Vega Martínez. Ingeniera Industrial. Coordinadora del proyecto CAPRI H2020
El impacto de la Inteligencia Artificial (IA) es altamente reconocido como uno de los motores clave de la revolución industrial digital junto con los datos y la robótica 1 2. Para aumentar el desarrollo de una IA que sea factible práctica y económicamente en los sectores industriales, necesitamos aplicaciones de IA con interfaces más simples, que no requieran una mano de obra altamente cualificada. Estas aplicaciones de IA deben tener una vida útil más larga y que requiera un mantenimiento menos especializado (por ejemplo, para el etiquetado de datos, entrenamiento, validación…)
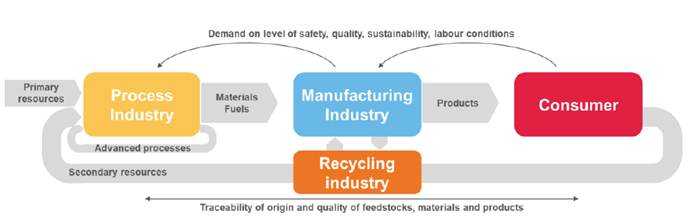
Lograr una implementación efectiva de tecnologías de IA confiablesdentro de la industria de proceso requiere una comprensión coherente de cómo estas diferentes tecnologías se complementan e interactúan entre sí en el contexto de los requisitos específicos del dominio que requieren los sectores industriales3.Las industria de proceso deben aprovechar el potencial de la innovación basada en IA, dentro del impulso de la transformación digital, como facilitador clave para alcanzar los objetivos del Green Deal y la esperada transición verde y digital necesaria para una evolución completa hacia la economía circular.
Uno de los retos más importantes para el desarrollo de soluciones innovadoras en la industria de proceso es la complejidad, inestabilidad y imprevisibilidad de sus procesos y el impacto en sus cadenas de valor. Estas soluciones normalmente requieren: funcionar en condiciones adversas, bajo cambios en los valores de los parámetros del proceso, falta de monitoreo/medición consistente de algunos parámetros importantes para analizar el comportamiento del proceso y que son difíciles de medir en tiempo real. A veces, dichos parámetros solo están disponibles a través de análisis de control de calidad en laboratorios que son los responsables de vigilar la trazabilidad del origen y calidad de materias primas, materiales y productos.
Para las aplicaciones basadas en IA, estas restricciones son más críticas, ya que la IA requiere (generalmente) una cantidad considerable de datos de alta calidad para asegurar el rendimiento del proceso de aprendizaje (en términos de precisión y eficiencia). Además, obtener datos de alta calidad, generalmente requiere una participación intensiva de expertos humanos para curar (o incluso crear) datos en un proceso que requiere mucho tiempo. Asimismo, un proceso de aprendizaje supervisado requiere el etiquetado/clasificación de ejemplos de entrenamiento por parte de expertos en el dominio, lo que hace que una solución de IA pueda no ser rentable.
Minimizar (tanto como sea posible) la participación humana en el ciclo de creación de la IA implica algunos cambios fundamentales en la organización de su ciclo de vida, especialmente desde el punto de vista de lograr una IA más autónoma, lo que conduce al concepto de self-X-AI4. Para lograr tal comportamiento autónomo para cualquier tipo de aplicación, generalmente se necesita dotar de habilidades avanzadas (denominadas self-X en inglés y traducidas como auto-X) como las propuestas para la computación autonómica (AC, del inglés Autonomic Computing)5:
Habilidades self-X de computación autonómica
Auto-Configuración: (para facilitar la integración de nuevos sistemas de adaptación al cambio)
Auto-Optimización: (control automático de recursos para un funcionamiento óptimo)
Auto-Recuperación: (detección, diagnóstico y reparación para corrección de errores)
Auto-Protección: (identificación y protección de ataques de una manera proactiva)
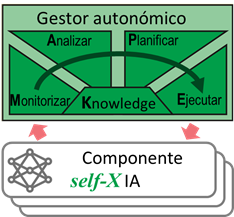
Por lo tanto, el paradigma de la computación autonómica puede ayudar en muchas tareas de IA a través de una gestión adecuada 6 7 . En este escenario, la IA actúa como el sistema de procesamiento inteligente y el gestor autonómico ejecuta continuamente un ciclo de Monitoreo-Análisis-Planificación-Ejecución basado en el conocimiento (MAPE-K) del sistema IA controlado, con el objetivo de desarrollar una aplicación IA auto-mejorada.
De hecho, estas nuevas aplicaciones de (self-X) IA serán, hasta cierto punto, autogestionadas para mejorar su propio rendimiento de forma incremental5. Esto se realizará mediante el ciclo de adaptación, que permita «aprender haciendo» utilizando el modelo MAPE-K y las habilidades self-X propuestas por la computación autonómica. El proceso de mejora debe basarse en la capacidad de auto-optimización continua (por ejemplo, ajuste de hiperparámetros en el aprendizaje automático). Además, en el caso de tener problemas en el funcionamiento de un componente de Inteligencia Artificial, el administrador autonómico debe activar las habilidades de auto-configuración (por ejemplo, elección del método de IA), auto-reparación (por ejemplo, detección de desviación del modelo entrenado) y auto-protección (por ejemplo, generar datos artificiales para mejorar los modelos entrenados) según sea necesario, basado en el conocimiento del sistema IA.
En tan solo unas semanas, CARTIF iniciará un proyecto con la ayuda de otras organizaciones expertas en IA y empresas líderes de varios sectores de la industria de proceso Europea para abordar estos desafíos y cerrar la brecha entre la IA y la automatización. El proyecto propone un enfoque novedoso para actualizar de forma continua aplicaciones de IA con una mínima intervención de expertos, a partir de una integración de datos para IA, y proporcionando capacidades de computación autonómica (self-X). La idea principal es permitir la actualización continua de las aplicaciones de IA mediante la integración de datos industriales del mundo físico con una intervención humana reducida.
Os informaremos en futuros posts de los avances que realizaremos con esta nueva generación de aplicaciones IA auto-mejoradas para la industria.