Imagina descubrir que el piloto de tu próximo vuelo estará usando el Apple Vision Pro mientras está al mando del avión. ¿Te sentirías cómodo subiendo a ese avión? Si tu respuesta es no, es posible que pienses que el piloto es un imprudente y tu vida está en riesgo. Por otro lado, si respondes si, es probable que conozcas el potencial de emplear este dispositivo en dicha situación.
Recientemente el mundo se vio envuelto en este debate cuando un piloto en Estados Unidos fue grabado usando el Apple Vision Pro durante un vuelo. El piloto en cuestión afirmaba haber mejorado su productividad con este dispositivo1. Sin embargo, recibió críticas significativas y tuvo que disculparse tras eliminar el vídeo.
¿Por qué este caso indignó tanto? En realidad, son muchos los sectores donde se utilizan este tipo de dispositivos diariamente, como la cirugía, la arquitectura, la ingeniería y la formación. La razón es simple: estamos progresando.Aunque los humanos somos escépticos ante nuevas tecnologías, reconocemos que pueden mejorar nuestras vidas. Un ejemplo claro es el comercio electrónico; cuando comenzó, muchas personas pensaban que era peligroso. Ahora, Amazon es la quinta empresa más valiosa de Estados Unidos y en España, el 39% de la población compra de manera online al menos una vez al mes2.
Es probable que con el tiempo este sentimiento también se disipe en el caso de la realidad extendida. Este término, que engloba la realidad virtual, realidad aumentada y realidad mixta, puede resultar confuso para muchos. Cada tecnología tiene un propósito específico basado en el nivel de inmersión: la realidad virtual crea entornos completamente digitales, la realidad aumentada superpone elementos digitales en la realidad física y la realidad mixta combina ambas para dar conciencia espacial a los elementos digitales. Este concepto comprende mejor si se observa la siguiente imagen.
Diferencias entre realidad virtual, aumentada y mixta. Fuente: Avi Barel3
En la imagen, se puede apreciar cómo en realidad mixta, un objeto como un pato de goma puede reconocer su entorno y posicionarse detrás de una mesa en lugar de atravesarla como lo haría en realidad aumentada. ¡Esta es la magia de la realidad mixta!
Aunque el Apple Vision Pro tiene características increíbles, dispositivos similares existen desde hace tiempo, algo que en CARTIF se sabe bien. Por eso, desde hace tiempo en la División de Sistemas Industriales y Digitales empleamos el dispositivo de realidad mixta Microsoft HoloLens 2, para cumplir diversos propósitos.
En el proyecto Baterurgia, estamos usando esta tecnología para automatizar el desmontaje de baterías de coches eléctricos y, favoreciendo la interacción humano-robot. Para lograrlo. nos apoyamos en la robótica y la visión artificial para detectar los tornillos presentes en una batería. A través de las lentes del Microsoft Hololens 2, el operario observa hologramas que indican la posición de los tornillos en el espacio. El operario puede seleccionar un tornillo con el dedo o la mirada y dar órdenes al robot mediante comandos de voz. El sistema ofrece retroalimentación sobre el progreso de la actividad, permitiendo que el operario realice otras tareas simultáneamente.
Secuencia de recogida de un tornillo (Grabado con Microsoft HoloLens 2)
Visualización de la imagen de la cámara con los tornillos detectados.
Señalización de los tornillos.
El operario elige un tornillo.
El robot recoge el tornillo elegido.
Como has visto, la realidad mixta está ganando popularidad y se está aplicando en más sectores. El alto costo de productos como Apple Vision Pro y Microsoft Hololens 2, que rondan los $3500, es una limitación importante. No obstante, nuevos dispositivos más asequibles como Meta Quest 3, que cuesta alrededor de $500, están haciendo que esta tecnología sea más accesible para empresas y usuarios. En esta línea, se prevé que la cantidad de ventas mundiales de dispositivos de realidad extendida aumente a 105 millones para 20254.
Si este post te ha intrigado y deseas explorar más sobre la realidad extendida y su impacto, ¡Estaré encantado de compartir más información contigo!
Cuando un proyecto finaliza, es el momento de recapitular, de recopilar toda la información y la experiencia adquirida durante el proceso. A lo largo de los tres años y medio de trabajo en el proyecto CAPRI, ha habido mucho tiempo para hacer cosas, para obtener muy buenos resultados o para sentirse mal porque muchas veces nada parece funcionar bien a la primera.
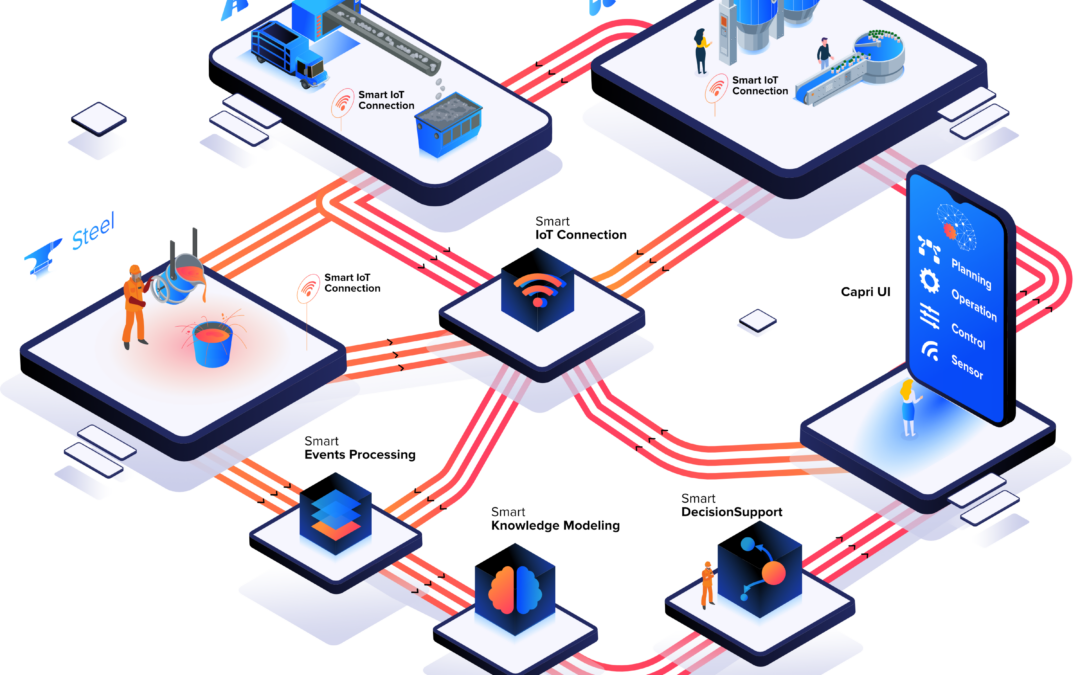
El proyecto CAPRI finalizó en septiembre de 2023 y logró sus principales objetivos definidos al inicio, que fueron impulsados por la necesidad de ayuda en la transformación digital de la industria europea de procesos mediante la investigación, desarrollo y prueba de una plataforma de automatización cognitiva, CAP, que integra 19 soluciones cognitivas diferentes definidas en cada una de las tres plantas piloto del proyecto. Esta plataforma se ha diseñado para lograr el objetivo final de obtener reducciones en el uso de materias primas, consumo de energía y huella de CO2. Tras finalizar el proyecto, se ha demostrado que las reducciones se han logrado gracias a la estrecha colaboración de los doce socios involucrados, procedentes de siete países diferentes. La plataforma cognitiva y las soluciones se implementaron en tres sectores importantes de la industria de procesos: fabricación de asfalto, producción de lingotes y barras de acero y producción de tabletas en la industria farmacéutica.
Por ejemplo, en la planta piloto de asfalto de EIFFAGEInfraestructuras, las soluciones cognitivas estaban relacionadas con los cuatro niveles de automatización, desde sensores hasta planificación, abarcándolos todos. El prototipo final demostrado bajo operación real de la planta de asfalto incluyó tecnologías muy diferentes como visión por computadora, análisis de vibraciones, redes neuronales o modelos matemáticos para la parametrización de los datos existentes para predecir los indicadores clave de rendimiento (consumo específico de energía por tonelada de mezcla de asfalto o la cantidad final de materias primas utilizadas).
Las soluciones cognitivas desarrolladas, como el control cognitivo del tambor secador o los nuevos sensores, aseguran la calidad de los productos y la producción en tiempo real, reduciendo el consumo de energía y materias primas utilizadas. Antes del proyecto, el control de los materiales utilizados se basaba en estimaciones y ahora, con el modelo matemático para el balance de masas y los nuevos sensores, los operadores de la planta pueden recibir una información en tiempo real que no tenían antes.
Los resultados esperados de cada solución cognitiva se definieron durante las primeras etapas del proyecto para verificar las mejoras de cada una durante el período de validación del proyecto. El proyecto CAPRI ofrece soluciones innovadoras que tienen el potencial de transformar industrias e impulsar el progreso. Destaca el enfoque del proyecto en desbloquear nuevas posibilidades y capacitar a varios sectores con avances de vanguardia gracias a los resultados explotables clave generados.
Respecto a estos resultados, dentro del caso de uso de asfalto, se incluyeron como resultados explotables tres soluciones: un sensor para medir el polvo aspirado en línea dentro de un tubo, la cantidad de betún presente en el asfalto reciclado y un sistema de mantenimiento predictivo del colector de polvo de la planta basado en sensores cognitivos y conocimientos expertos. El caso de uso del acero generó dos resultados explotables: un sensor cognitivo de solidificación de acero para procesos de colada continua y un seguimiento de productos de acero. El caso de uso de la industria farmacéutica tiene dos resultados explotables: un sensor cognitivo para la calidad de los gránulos y un sensor de atributos de calidad.
El proyecto también generó algunos resultados explotables clave transversales útiles para cualquier tipo de industria: la arquitectura técnica de la plataforma de automatización cognitiva o CAP, y otro relacionado con los datos abiertos generados, mostrando el compromiso del proyecto CAPRI con la ciencia abierta y los principios FAIR a través de la generación de más de 50 activos compartidos en plataformas abiertas, como Zenodo.
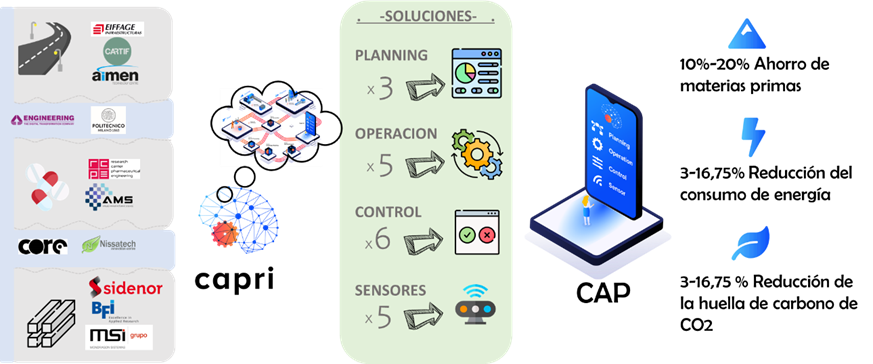
Los principales objetivos de la propuesta fueron la reducción del uso de materias primas, energía y huella de CO2. Podemos decir con orgullo que logramos esos objetivos, como se puede ver en la tabla resumen de KPIs después de CAPRI:
KPI Objetivo
Después de CAPRI
5% – 20% Ahorro de materias primas
10-20%
5% reducción del consumo de energía
3-16,75%
5% reducción de la huella de carbono de CO2
3-16,75%
Como ingeniero, cuando un proyecto finaliza a tiempo, y con estos muy buenos resultados, cuando su proyecto ha contribuido a mejorar la industria, sin dañar nuestro medio ambiente, uno se siente mejor y todos los sacrificios, horas extras y críticas negativas valieron la pena.
«Un ciudadano de Los Ángeles descubre el rayo de la muerte». Este impactante titular apareció en un periódico de Los Ángeles en julio de 1960. Unas semanas antes, concretamente el 16 de mayo de 1960, el ingeniero y físico americano Theodore H. Maiman en los laboratorios de investigación de Hughes había conseguido que un cilindro de rubí sintético son bases reflectantes y una lámpara de fotografía emitiera pulsos de luz roja intensa lo que constituyó la primera implementación física del láser.
Theodore H. Maiman con la primera implementación de un láser
Este hito en la fotónica fue consecuencia tanto de siglos de estudio de grandes científicos como Newton, Young, Maxwell o Einstein tratando de conocer y explicar la naturaleza luz, como de una frenética carrera desde los años 50 entre una docena de laboratorios con los de Bell a la cabeza por demostrar experimentalmente que la emisión estimulada de la luz predicha por Albert Einstein en su trabajo de 1917 «The Quantum Theory of Radiation» era posible.
El término LASER o «Light Amplified by Stimulated Emission of Radiation» fue acuñador por Gordon Gould en 1957 en sus notas sobre la viabilidad de la construcción de un láser. Gould había sido estudiante de doctorado de Charles Townes, quien, en 1954, había construido el MASER, predecesor del láser, que amplificaba las ondas microondas por emisión estimulada de la radiación. Finalmente, Charles Townes recibiría en 1964 el Nóbel de física por su implementación del MASER, Gordon Gould se haría millonario con la patente del láser y Mainman recibiría el reconocimiento de haber realizado la primera implementación de un láser, además de numerosos reconocimientos académicos.
Un láser es una fuente de luz con unas características especiales de coherencia, monocromicidad y colimación. Estas características permiten concentrar con la ayuda de lentes ópticas una gran intensidad de energía en un área mínima. Para conseguir estas características, el láser hace uso del mecanismo cuántico predicho por Einstein con el que se consigue que la generación de fotones en ciertos medios sólidos, líquidos o gaseosos se amplifique en gran medida cuando dichos medios son excitados eléctricamente o mediante pulsos de luz.
Durante los años 60, además del láser de estado sólido de Maiman, se desarrollaron otros láseres como el láser de He-Ne en diciembre del 60 y el láser de CO2 en 1961 cuyo medio activo eran gases o el láser de diodo en 1962. Aunque en principio se dijo del láser que era «una solución para un problema no definido», rápidamente el número de aplicaciones de este incremento en gran medida haciendo de este una herramienta imprescindible en la mayoría de los campos de la ciencia y fabricación. Podemos encontrar ejemplos de esto en la industria, donde sus múltiples usos para cortar, soldar o para tratamientos superficiales de gran número de materiales los ha hecho imprescindibles o en el sector de las comunicaciones donde su uso como emisor de información mediante pulsos de luz a través de fibras ópticas ha permitido conseguir tasas de transferencia de datos inimaginables sin las cuales no sería posible la actual transformación digital.
Actualmente, el desarrollo de nuevos láseres, las prestaciones y sus aplicaciones sigue creciendo. Por ejemplo, en los últimos años, los láseres verdes y azules están cobrando mucha importancia en la electro movilidad ya que sus longitudes de onda son más adecuadas para las soldaduras de elementos de cobre en comparación con otros láseres más habituales.
Láser verde para corte y soldadura de elementos de cobre. Fuente: Cvecek, Kaufamnn Blz 2021. https://www.wzl.rwth-aachen.de/go/id/telwe?lidx=1
Desde el 2020 CARTIF forma parte de PhotonHub Europe, una plataforma formada por más de 30 centros de referencia en fotónica de 15 países europeos en el que más de 500 expertos en fotónica ofrecen su apoyo a empresas (principalmente PYMES) para ayudarlas a mejorar sus procesos productivos y productos a través del uso de la fotónica. Para ello se han articulado hasta el año 2024 acciones formativas, de desarrollo de proyectos y de asesoramiento a nivel técnico y financiero. Por otro lado, para estar al tanto de lo que ocurre en el mundo de la fotónica os animamos a formar parte de la comunidad creada en PhotonHub Europe. En esta comunidad podéis estar al tanto de las actividades de la plataforma como de noticias y eventos relaciones con la fotónica.
En un mundo donde los seres humanos llevamos a cabo tareas que involucran la manipulación de objetos, como alzarlos, arrastrarlos o interactuar con ellos (por ejemplo, cuando usamos nuestros queridos móviles o nos comemos una manzana), estas acciones se ejecutan de manera inconsciente, de forma natural. Son nuestros sentidos los que nos permiten adaptar nuestras características físicas a las tareas de manera instintiva. En contraste, los robots actúan como pequeños aprendices de humanos, imitando nuestro comportamiento, ya que actualmente carecen de la misma consciencia e inteligencia.
Para abordar esta brecha, emergió la «Interacción Humano Robot» (HRI, por sus siglas en inglés), una disciplina que busca comprender, diseñar y evaluar la interacción entre robots y seres humanos. Este campo tuvo sus inicios en la década de los 90´s con un enfoque multidisciplinar, pero hoy en día su estudio está en constante evolución y ha dado lugar a importantes eventos1 donde se reúnen visionarios en la temática, que buscan impulsar esta tecnología, acercándonos cada vez más a un mundo donde la inteligencia artificial y los seres humanos se entiendan y colaboren transformando nuestro futuro cercano.
Es importante comprender que esta disciplina de la interacción humano robot no es una tarea sencilla, sino tremendamente desafiante, ya que requiere a su vez de la contribución de las ciencias cognitivas, la lingüística, la psicología, la ingeniería, las matemáticas, la informática y el diseño de los factores humanos, por lo que existen múltiples atributos involucrados, como son:
Nivel de autonomía: toma de decisiones de forma independiente.
Intercambio de información: fluidez y entendimiento entre las diferentes partes.
Diferentes tecnologías y equipos: mayor adaptación entre lenguajes y modelos.
Configuración de tareas: definición y ejecución de tareas de manera eficiente.
Aprendizaje cognitivo: habilidades para aprender y mejorar con el tiempo.
También en este caso toma especial importancia el tipo de interacción, que se define como, acción, relación o influencia recíproca entre dos o más personas, objetos, agentes, etc. y un factor clave es la distancia entre humano y robot, donde se puede denominar interacción a distancia, por ejemplo, robots móviles que se envían al espacio, o por el contrario una interacción de manera física, cuando el ser humano tiene contacto con el robot.
Niveles de interacción entre humano y robot de acuerdo a los estándares definidos en ISO8373//10218//15066. Fuente: V. Villani, et al., Survey on human–robot collaboration in industrial settings: Safety, intuitive interfaces and applications, Mechatronics 55 (2018) 248–266,http://dx.doi.org/10.1016/j.mechatronics.2018.02.009
Estos atributos son solo una muestra de las complejidades que involucran estos sistemas de interacción robótica, donde la colaboración interdisciplinaria es esencial para su evolución.
Desafíos de la interacción entre humanos y robots
En este momento los desafíos están relacionados con la naturaleza altamente desestructurada de los escenarios donde se utilizan los robots colaborativos, ya que es imposible para un desarrollador tecnológico estructurar todo el entorno del sistema. Entre los más importantes retos se encuentran aspectos relacionados con movilidad, comunicaciones, construcciones de mapas y la conciencia de la situación.
Entonces, ¿cuál es el siguiente paso en las interacciones humanos-robots? Algunos desafíos son: conseguir que hablen el mismo idioma, esto implica mejoras y simplificación de la comunicación, especialmente en el caso de personas no entrenadas tecnológicamente, no presuponer estas habilidades previas y que no necesiten complicados manuales de instrucciones; también descubrir nuevas formas de interacción, mediante lenguaje natural, en el caso de los robots de asistencia, especial cuidado por la proximidad y vulnerabilidad; en general mejorar las interfaces, hacerlas más ágiles y flexibles, para poder ser adaptadas de forma sencilla a diferentes escenarios y cambios de entorno.
Por otro lado, un desafío que cobra especial importancia en los últimos tiempos es tener en cuenta las necesidades emocionales, valores humanos y ética en las interacciones entre humanos y robots, como se destacó anteriormente en esta definición de HRI.
Definición HRI (Interacción Humano-Robot)
es la ciencia que estudia el comportamiento y las actitudes de las personas hacia los robots en relación con sus características físicas, tecnológicas e interactivas, con el objetivo de desarrollar robots que faciliten el surgimiento de interacciones humano-robot eficientes (de acuerdo con los requisitos originales de su área prevista de uso), pero también sean aceptables para las personas y satisfagan las necesidades sociales y emocionales de sus usuarios individuales, respetando al mismo tiempo los valores humanos (Dautenhahn, 2013).
Inspirados por este apasionante campo de trabajo, CARTIF, en colaboración con la Fundación FIWARE y otros socios punteros en Europa, comenzará en 2024 el proyecto europeo ARISE, que pretende conseguir tecnologías de código abierto en tiempo real, ágiles y centradas en el ser humano, que impulsen soluciones en interacción Humano-Robot HRI combinando tecnologías abiertas como ROS2, Vulcanexus y FIWARE. Y donde se pretenden resolver retos mediante financiación de experimentos que desarrollen soluciones HRI ágiles con interfaces cada vez más adaptables e intuitivas.
ARISE abordará muchos de los siguientes desafíos: (1) Aplicación de robótica colaborativa para desmontaje de productos de valor añadido, (2) Picking de productos complejos en almacenes industriales, (3) Colaboración robótica flexible para un ensamblado y control de calidad más eficiente, (4) Reprogramación inteligente asegurando la adaptabilidad para diferentes productos mediante interfaces intuitivas, (5) Tareas de búsqueda y transporte en entornos sanitarios, (6) Mejora de la interacción multimodal en torno a diferentes tareas funcionales, (7) Asistencia robótica en tareas flexibles de alta precisión y (8) mejora de la ergonomía y la eficiencia de los trabajadores, generando así un marco de trabajo multidisciplinar que tiene en cuenta aspectos tanto tecnológicos como sociales.
Además, el proyecto ARISE abre sus puertas a los expertos en robótica para que puedan colaborar con la resolución de los diversos desafíos, generando así nuevos componentes tecnológicos para la HRI Toolbox, como ROS4HRI. Este gran reto colaborativo tiene como objetivo facilitar a las empresas la creación ágil y sostenible de aplicaciones HRI en un futuro cercano.
1ACM/IEEE International Conference on Human-Robot Interaction, IEEE International Conference on Robotics and Automation (ICRA) y Robotics Systems and sciences
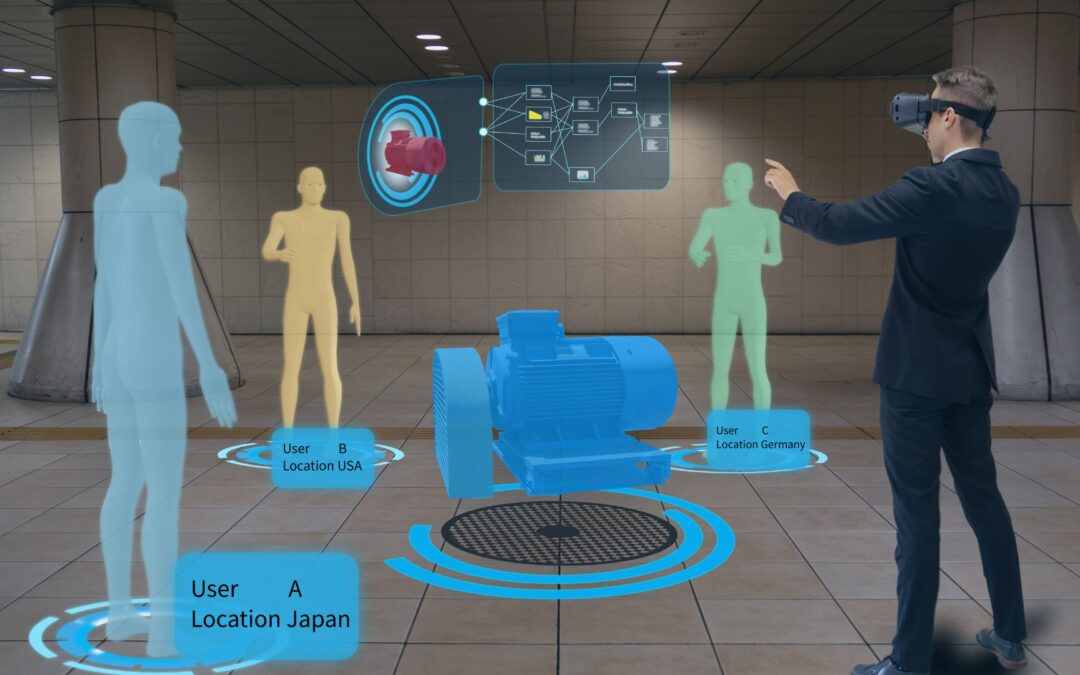
El gemelo digital se ha convertido en una de las principales tendencias o «modas» en relación con la digitalización. Prácticamente es un sinónimo de producto, algo que puedes adquirir como un bien más para una empresa. En CARTIF, creemos que el concepto de gemelo digital es un sinónimo del paradigma de la industria 4.0, un enfoque «revolucionario» que ha transformado la forma en que concebimos y gestionamos los procesos industriales.
El término «gemelo digital» fue acuñado porJohn Vickers de la NASA en 2010, pero su predecesor, el ciclo de vida de un producto, fue introducido por Michael Grieves en 2002. Esta filosofía se centraba en gestionar un producto a lo largo de su vida, desde su creación hasta su eliminación. En esencia, el producto físico genera datos que alimentan un espacio virtual, proporcionando información esencial para la toma de decisiones y la optimización del objeto físico.
Una definición de gemelo digital podría ser: «representación digital precisa y completa de objetos físicos, procesos o sistemas con datos en tiempo real y características físicas, comportamientos y relaciones«.
Una pregunta clave es ¿por qué necesitamos gemelos digitales? o ¿cuál es su utilidad? Estas representaciones digitales precisas y en tiempo real ofrecen una serie de ventajas:
Recopilación y análisis de datos para obtener información valiosa y generar conocimiento, lo que impulsa la eficiencia y la toma de decisiones informadas.
Simulación precisa y dinámica del comportamiento de objetos físicos, lo que posibilita pruebas y experimentos virtuales antes de implementar cambios, como inversiones costosas, en el mundo real.
Reducción de costos y riesgos minimizando estos últimos y acelerando la innovación den una amplia gama de sectores, desde la manufactura hasta la atención médica.
Actualización en tiempo real de forma constante a medida que se recopilan nuevos datos del objeto físico, lo que garantiza su validez a lo largo de su ciclo de vida.
Al igual que las revoluciones industriales anteriores, la industria 4.0 ha transformado la forma en que trabajamos. Esta cuarta revolución se centra en la interconexión de sistemas y procesos para lograr una mayor eficiencia en toda la cadena de valor. La fábrica ya no es una entidad aislada, sino un nodo en una red global de producción.
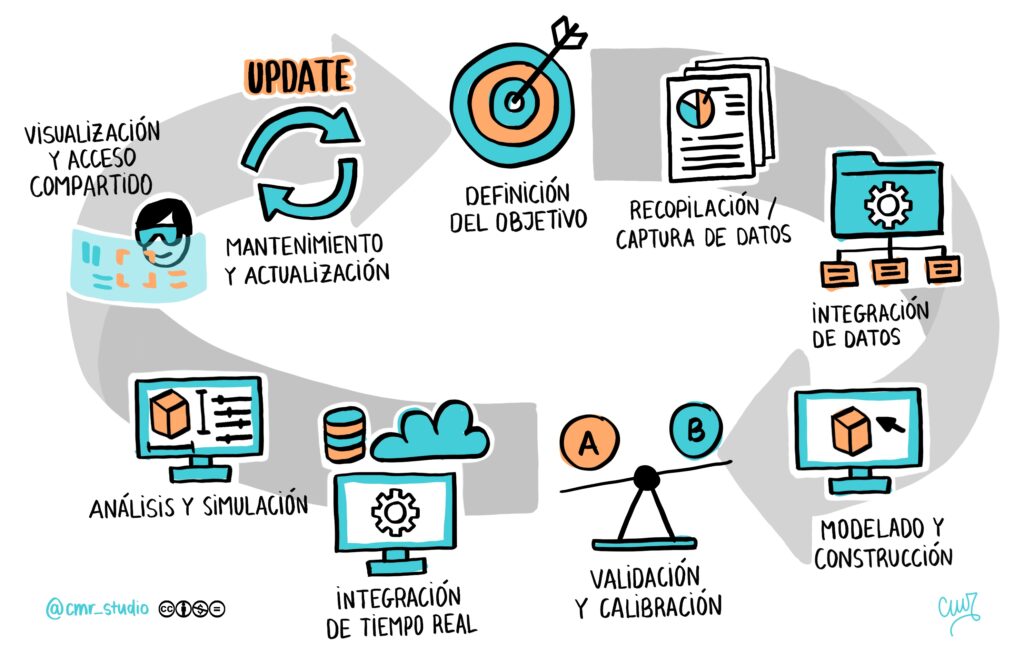
Para crear un gemelo digital efectivo, seguimos una receta sistemática de nueve pasos en CARTIF:
Definición del objetivo: identificamos el objeto físico, proceso o sistema que deseamos replicar y comprendemos claramente su propósito y objetivos.
Recopilación de datos: recolectamos todos los datos relevantes del objeto físico utilizando sensores IoT, registros históricos u otras fuentes de información.
Integración de datos: organizamos y combinamos los datos recopilados en un formato adecuado para su procesamiento y análisis.
Modelado y construcción: utilizamos diferentes tecnologías de simulación y modelado para crear una representación digital precisa del objeto físico.
Validación y calibración: verificamos y ajustamos el modelo del gemelo digital utilizando datos de referencia y pruebas comparativas con el objeto físico real.
Integración en tiempo real: establecemos una conexión en tiempo real entre el gemelo digital y los sensores IoT del objeto físico para recopilar datos en tiempo real.
Análisis y simulación: utilizamos el gemelo digital para realizar análisis, simulaciones y pruebas virtuales del objeto físico.
Visualización y acceso compartido: proporcionamos interfaces virtuales y herramientas de acceso compartido para que los usuarios interactúen con el gemelo digital.
Mantenimiento y actualización: mantenemos el gemelo digital actualizado mediante una recopilación de datos en tiempo real, la calibración periódica y la incorporación de mejoras y actualizaciones.
Así como las revoluciones industriales anteriores requerían tecnologías habilitadoras, la industria 4.0 necesita sus propios habilitadores digitales. Como hemos dicho al principio consideramos al gemelo digital una forma digitalizada del paradigma industria 4.0 porque los habilitadores digitales son fundamentales para la creación de gemelos digitales de forma eficaz. En CARTIF, hemos acumulado casi 30 años de experiencia aplicando estas tecnologías en diversos sectores, desde la industria hasta la salud.
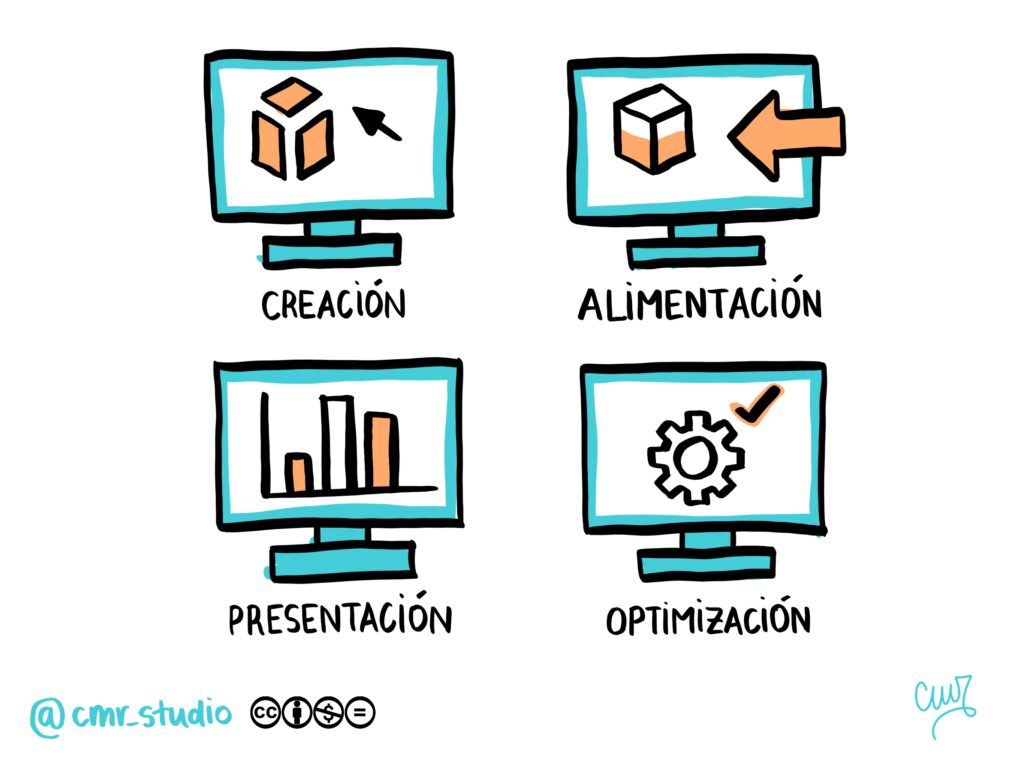
Las tecnologías habilitadores digitales se dividen en cuatro categorías principales:
Tecnologías de creación: estas tecnologías permiten la creación de gemelos digitales mediante ecuaciones físicas, datos, modelado 3D o eventos discretos.
Optimización: la optimización se logra a través de métodos como la programación lineal/no lineal, simulaciones, algoritmos de IA y enfoques heurísticos.
Presentación: la información generada puede presentarse a través de soluciones comerciales, herramientas de código abierto como Grafana o Apache Superset o incluso visualizaciones de realidad aumentada.
A pesar de los avances, el desafío de mantener los gemelos digitales actualizados sigue siendo un área de desarrollo. La actualización automática para reflejar la realidad es un objetivo que requiere una inversión significativa en investigación y desarrollo.
En resumen, los gemelos digitales son el corazón de la industria 4.0, impulsando la eficiencia y la toma de decisiones informadas. En CARTIF, estamos comprometidos a seguir liderando el camino en este emocionante campo, ayudando a diversas industrias a abrazar el futuro digital.
En el campo de la salud, se sabe que es mucho más efectivo prevenir enfermedades que tratarlas una vez que ya se han manifestado. De manera similar, se puede aplicar en el contexto de los datos industriales, su mantenimiento continuo y proactivo ayuda a evitar la necesidad de un extenso pre-tratamiento antes de utilizar técnicas avanzadas de analítica de datos para toma de decisiones y generación de conocimiento.
El pre-tratamiento de los datos implica realizar diversas tareas como: (1) limpieza de datos, (2) corrección de errores, (3) eliminación de valores atípicos y (4) la normalización de formatos, entre otros. Estas actividades son necesarias para asegurar la calidad y la coherencia de los datos antes de utilizarlos en análisis, toma de decisiones o aplicaciones específicas.
Fuente: Storyset en FreePik
Sin embargo, si se puede implementar un mantenimiento sólido de los datos desde el principio, se pueden prevenir muchas de estas irregularidades y errores. Al establecer procesos adecuados de ingreso de datos, aplicar validaciones y controles de calidad, y mantener registros actualizados, es posible reducir la cantidad de pre-tratamiento necesario posteriormente, identificando y abordando problemas potenciales antes de que se conviertan en obstáculos importantes. Esto incluye detección temprana de errores como datos inexactos, corrección de inconsistencias y actualización de información obsoleta. Es cierto que en la actualidad las empresas almacenan grandes cantidades de datos pero es importante destacar que no todos esos datos son necesariamente válidos o útiles, por ejemplo, para ser usados en un proyecto de inteligencia artificial. De hecho, muchas organizaciones se enfrentan al desafío de mantener y gestionar datos que carecen de relevancia o calidad. Esta gestión tiene como objetivo garantizar la integridad, calidad y disponibilidad de los datos a lo largo del tiempo.
Un mantenimiento eficiente de los datos es crucial para garantizar que éstos sean confiables, actualizados y precisos, pero ello implica una supervisión y gestión continuas por parte del personal de la empresa, asegurándose de que sigan siendo precisos, coherentes, completos y actualizados. Las actividades más comunes relacionadas con el mantenimiento de datos incluyen:
Monitoreo regular: Se realiza un seguimiento periódico de los datos para detectar posibles problemas, como errores, inconsistencias, pérdidas o valores atípicos. Esto puede implicar la revisión de informes, análisis de tendencias o la implementación de alertas automatizadas para detectar anomalías.
Actualización y corrección: Si se identifican errores o inconsistencias en los datos, el personal de mantenimiento se encargará de corregirlos y actualizarlos de manera adecuada. Esto puede implicar la revisión de registros, la verificación de fuentes externas o la comunicación con los responsables de la recopilación de datos.
Respaldo y recuperación: Se establecen procedimientos y sistemas para realizar copias de seguridad de los datos y garantizar su recuperación en caso de fallos o pérdidas. Esto puede incluir la implementación de políticas de respaldo regular y la realización de pruebas periódicas de recuperación de datos.
Gestión de accesos y seguridad: El personal de mantenimiento de datos se asegura de que los datos estén protegidos y solo sean accesibles por usuarios autorizados. Esto puede implicar la implementación de medidas de seguridad, como el control de accesos, el cifrado de datos o la supervisión de registros de auditoría.
Actualización de documentación y metadato: Se mantiene actualizada la documentación relacionada con los datos, incluyendo la descripción de los campos, la estructura de la base de datos y los metadatos asociados, Esto facilita la comprensión y utilización adecuada de los mismos por parte de los usuarios.
En resumen, el mantenimiento de datos implica: (1) supervisar regularmente, (2) corregir errores, (3) respaldar y (4) asegurar los datos para garantizar que estén en buen estado y sean confiables. Estas acciones son fundamentales para mantener la calidad y la seguridad de la información almacenada.
En CARTIF, nos enfrentamos a este tipo de problemas de diferentes proyectos relacionados con la optimización de procesos de fabricación para diferentes empresas e industrias. Somos conscientes de la cantidad de tiempo consumido en horas de personal debido a la problemática explicada, por lo que estamos trabajando en dotar de ciertos mecanismos automáticos que hagan la vida más fácil a los responsables del citado «mantenimiento de datos». Un ejemplo se encuentra en el proyecto s-X-AIPI centrado en el desarrollo de soluciones de IA con capacidades auto y que requieren una especial atención a la calidad de los datos empezando por la ingesta de éstos.
Co-autores
Mireya de Diego. Investigadora de la División de Sistemas Industriales y Digitales.
Aníbal Reñones. Director del área de Industria 4.0 de la División de Sistemas Industriales y Digitales.