Imagina que cada producto que llega a tus manos pudiera explicarte su historia: de dónde viene, con qué materiales se fabricó, qué procesos atravesó, cómo se garantizó su calidad y bajo qué condiciones fue transportado hasta su destino.
Vivimos en una era en la que la información lo es todo. Sin embargo, en el mundo industrial aún dejamos que muchos datos valiosos se pierdan entre sistemas aislados y decisiones urgentes. ¿Y si pudiéramos hacer que esos datos fueran visibles, útiles y conectados?
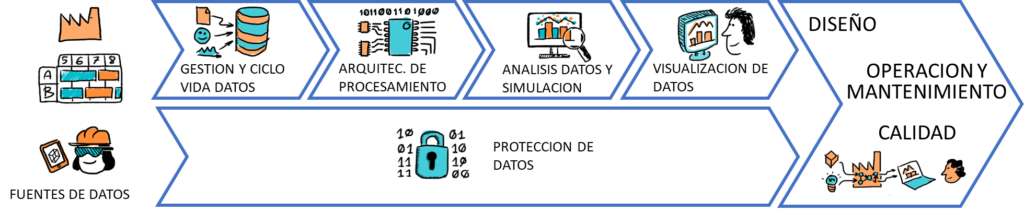
Hoy, gracias a tecnologías como la Industria 4.0 o los sistemas de captura en tiempo real, las plantas de producción generan más información que nunca. Pero tener datos no basta. La clave está en estructurarlos, interpretarlos y relacionarlos. Convertir datos dispersos en conocimiento útil es el primer paso hacia un etiquetado digital realmente inteligente.
Esto es precisamente lo que se busca en el proyecto europeobiOSpace: desarrollar un sistema de etiquetado digital para productos bio-basados que permita seguir el rastro de cada lote desde su origen hasta su entrega. Este sistema no solo recogerá información técnica sobre materias primas, procesos y controles de calidad, sino que también incluirá datos logísticos, condiciones de transporte y métricas medioambientales.
¿Por qué es necesario el etiquetado digital?
En los procesos industriales actuales, gran parte de la información clave sobre la fabricación de un producto se encuentra dispersa en distintas plataformas o no se registra de forma estructurada. Esto dificulta la trazabilidad completa de lo que ocurre en planta y, en consecuencia, complica la toma de decisiones operativas, la mejora continua o la justificación de estándares de sostenibilidad y calidad. En el contexto de la producción bio-basada, donde los materiales pueden variar en función del proveedor, la cosecha o el proceso, tener control sobre cada etapa del ciclo de vida del producto se vuelve especialmente importante. De ahí la necesidad de establecer un sistema que permita recopilar y consultar toda esta información de forma unificada y accesible.
¿Qué tipo de información se recopilará?
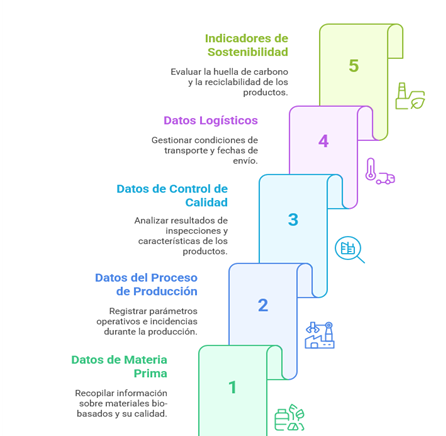
El sistema de etiquetado digital que se está diseñando en biOSpace contempla cinco bloques de información esenciales:
Todos estos datos se vinculan mediante un identificador digital único que acompaña al producto a lo largo de todo su recorrido, desde su entrada en fábrica hasta su salida. Esta etiqueta se va completando progresivamente, añadiendo información a medida que el producto atraviesa diferentes etapas del proceso: recepción de materia prima, transformación, control de calidad, embalaje, transporte, etc.
Esta estructura modular del identificador permite trazar con precisión el recorrido y condiciones del producto en cada fase, haciendo que toda la información relevante esté conectada de forma clara y estructurada.
¿Qué se puede lograr gracias a una trazabilidad integral?
El valor de esta información no reside solo en almacenarla, sino en poder utilizarla de forma práctica y adaptada a cada necesidad. Por eso, uno de los objetivos es que el sistema pueda consultarse desde paneles internos que ayuden al personal de planta a tomar decisiones en tiempo real, y que al mismo tiempo pueda integrarse en entornos digitales más amplios, como sistemas de gestión o plataformas de gemelo digital.
Además, la misma etiqueta digital puede ofrecer diferentes niveles de información según el perfil del usuario que la consulta. Un operario podrá ver datos técnicos sobre el proceso o los controles de calidad, mientras que un responsable de sostenibilidad podrá acceder a indicadores ambientales, y un consumidor final podrá consultar un resumen accesible sobre el origen del producto, sus características y su trazabilidad.
Esta trazabilidad detallada permitirá también alimentar lo que ya empieza a conocerse como pasaporte digital de producto, una herramienta que gana relevancia en el marco de las políticas europeas hacia una economía circular y más transparente.
«Lo que hacemos hoy con nuestros datos marca el rumbo de lo que haremos mañana con nuestros productos»
Aunque esta solución todavía se encuentra en fase de diseño, parte de una pregunta sencilla pero importante: ¿qué estamos haciendo con toda la información que ya se genera en nuestras fábricas?
En muchos casos, los datos existen, pero no están conectados, no se comparten o simplemente no se utilizan. Este proyecto busca precisamente eso: darles sentido, organizarlos y ponerlos al servicio de quienes los necesitan, desde el operario que gestiona un lote hasta quien toma decisiones estratégicas o quien, al final de la cadena, consume el producto.
No se trata de incorporar tecnología por tendencia, sino de usarla con criterio. De construir herramientas que permitan entender mejor lo que producimos, cómo lo hacemos y con qué impacto, en un momento en el que la trazabilidad, la sostenibilidad y la transparencia ya no son opciones, sino condiciones para seguir avanzando.
En el campo de la salud, se sabe que es mucho más efectivo prevenir enfermedades que tratarlas una vez que ya se han manifestado. De manera similar, se puede aplicar en el contexto de los datos industriales, su mantenimiento continuo y proactivo ayuda a evitar la necesidad de un extenso pre-tratamiento antes de utilizar técnicas avanzadas de analítica de datos para toma de decisiones y generación de conocimiento.
El pre-tratamiento de los datos implica realizar diversas tareas como: (1) limpieza de datos, (2) corrección de errores, (3) eliminación de valores atípicos y (4) la normalización de formatos, entre otros. Estas actividades son necesarias para asegurar la calidad y la coherencia de los datos antes de utilizarlos en análisis, toma de decisiones o aplicaciones específicas.
Fuente: Storyset en FreePik
Sin embargo, si se puede implementar un mantenimiento sólido de los datos desde el principio, se pueden prevenir muchas de estas irregularidades y errores. Al establecer procesos adecuados de ingreso de datos, aplicar validaciones y controles de calidad, y mantener registros actualizados, es posible reducir la cantidad de pre-tratamiento necesario posteriormente, identificando y abordando problemas potenciales antes de que se conviertan en obstáculos importantes. Esto incluye detección temprana de errores como datos inexactos, corrección de inconsistencias y actualización de información obsoleta. Es cierto que en la actualidad las empresas almacenan grandes cantidades de datos pero es importante destacar que no todos esos datos son necesariamente válidos o útiles, por ejemplo, para ser usados en un proyecto de inteligencia artificial. De hecho, muchas organizaciones se enfrentan al desafío de mantener y gestionar datos que carecen de relevancia o calidad. Esta gestión tiene como objetivo garantizar la integridad, calidad y disponibilidad de los datos a lo largo del tiempo.
Un mantenimiento eficiente de los datos es crucial para garantizar que éstos sean confiables, actualizados y precisos, pero ello implica una supervisión y gestión continuas por parte del personal de la empresa, asegurándose de que sigan siendo precisos, coherentes, completos y actualizados. Las actividades más comunes relacionadas con el mantenimiento de datos incluyen:
Monitoreo regular: Se realiza un seguimiento periódico de los datos para detectar posibles problemas, como errores, inconsistencias, pérdidas o valores atípicos. Esto puede implicar la revisión de informes, análisis de tendencias o la implementación de alertas automatizadas para detectar anomalías.
Actualización y corrección: Si se identifican errores o inconsistencias en los datos, el personal de mantenimiento se encargará de corregirlos y actualizarlos de manera adecuada. Esto puede implicar la revisión de registros, la verificación de fuentes externas o la comunicación con los responsables de la recopilación de datos.
Respaldo y recuperación: Se establecen procedimientos y sistemas para realizar copias de seguridad de los datos y garantizar su recuperación en caso de fallos o pérdidas. Esto puede incluir la implementación de políticas de respaldo regular y la realización de pruebas periódicas de recuperación de datos.
Gestión de accesos y seguridad: El personal de mantenimiento de datos se asegura de que los datos estén protegidos y solo sean accesibles por usuarios autorizados. Esto puede implicar la implementación de medidas de seguridad, como el control de accesos, el cifrado de datos o la supervisión de registros de auditoría.
Actualización de documentación y metadato: Se mantiene actualizada la documentación relacionada con los datos, incluyendo la descripción de los campos, la estructura de la base de datos y los metadatos asociados, Esto facilita la comprensión y utilización adecuada de los mismos por parte de los usuarios.
En resumen, el mantenimiento de datos implica: (1) supervisar regularmente, (2) corregir errores, (3) respaldar y (4) asegurar los datos para garantizar que estén en buen estado y sean confiables. Estas acciones son fundamentales para mantener la calidad y la seguridad de la información almacenada.
En CARTIF, nos enfrentamos a este tipo de problemas de diferentes proyectos relacionados con la optimización de procesos de fabricación para diferentes empresas e industrias. Somos conscientes de la cantidad de tiempo consumido en horas de personal debido a la problemática explicada, por lo que estamos trabajando en dotar de ciertos mecanismos automáticos que hagan la vida más fácil a los responsables del citado «mantenimiento de datos». Un ejemplo se encuentra en el proyecto s-X-AIPI centrado en el desarrollo de soluciones de IA con capacidades auto y que requieren una especial atención a la calidad de los datos empezando por la ingesta de éstos.
Co-autores
Mireya de Diego. Investigadora de la División de Sistemas Industriales y Digitales.
Aníbal Reñones. Director del área de Industria 4.0 de la División de Sistemas Industriales y Digitales.