
Computer vision is a discipline that has made it possible to control different production processes in industry and other sectors for many years. Actions as common as the shopping process in a supermarket require vision techniques such as scanning barcodes.
Until a few years ago, many problems could not be solved in a simple way with classical vision techniques. Identifying people or objects located at different positions in images or classifying certain types of inhomogeneous industrial defects were highly complex tasks that often did not provide accurate results.
Advances in Artificial Intelligence (AI) have also accompanied the field of vision. While Alan Turing established the Turing test in 1950, where a person and a machine were placed behind a wall, and another person asked questions trying to discover who was the person and who was the machine, in computer vision through AI, systems capable of reproducing the behaviour of humans are sought.
One of the fields of AI is neural networks. Used for decades, it was not unitl 2012 that they began to play an important role in the field of vision. AlexNet1 , designed by Alex Krizhevsky, was one of the first networks to implement the 8-layer convolution filter design. Years earlier, a worldwide championship had been established where the strongest algorithms tried to correctly classify images from ImageNet2 , a database with 14 million images representing 1,000 different categories. While the best of the classical algorithms, using SIFT and Fisher vectors, achieved 50.9% accuracy in classifying ImageNet images, AlexNet brought the accuracy to 63.3%. This result was a milestone and represented the beginning of the exploration of Deep Learning (DL). Since 2012, the study of deep neural networks has deepened greatly, creating models with more than 200 layers of depth and taking ImageNet´ s classification accuracy to over 90% with the CoAtNet3 model. which integrates convolution layers with attention layers in an intelligent, deep wise way.
Turning to the relationship of modern computer vision models to AI, Dodge et. al (2017)4 found that modern neural networks classifying ImageNet images made fewer errors than humans themselves, showing that computer systems are capable of doing tasks better and much faster than people.
Among the most common problem solved by computer vision using AI are: image classification, object detection and segmentation, skeleton recognition (both human and object), one shot learning, re-identification, etc. Many of the problems are solved in two dimensions as well as in 3D.
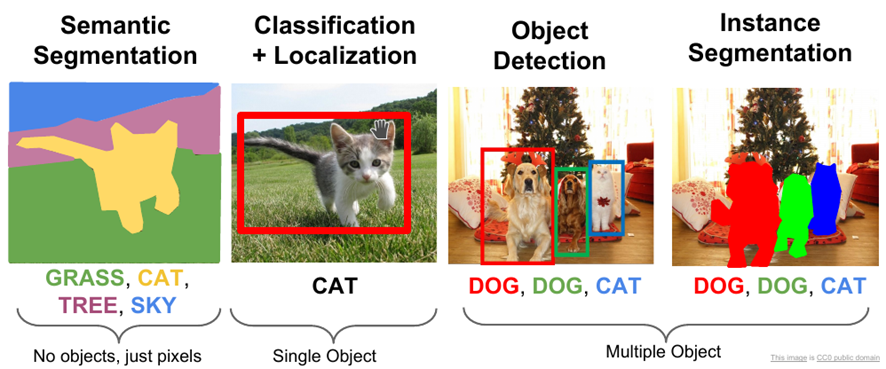
Classification simply tells us what an image corresponds to. So for example, a system could tell whether an image has a cat or a dog in it. Object detection allows us to identify several objects in an image and delimit the rectangle in which they have been found. For example, we could detect several dogs and cats. Segmentation allows us to identify the boundaries of the object, not just a rectangle. There are techniques that allow us to segment without knowing what is being segmented, and techniques that allow us to segment knowing the type of object we are segmenting, for example a cat.
Skeletal recognition allows a multitude of applications, ranging from security issues to the recognition of activities and their subsequent reproduction in a robot. In addition, there are techniques to obtain key points from images, such as points on a person´ s face, or techniques to obtain three-dimensional orientation from 2D images.

One Shot Learning allows a model to classify images from a single known sample of the class. This technique, typically implemented with Siamese neural networks, avoids the need to obtain thousands of images of each class to train a model. In the same way, re-identification systems are able to re-identify a person or object from a single image.
The high computational cost of DL models led early on to the search for computational alternatives to CPUs, the main processors in computers. GPUs, or graphics processing units, which were originally developed to perform parallel computations for smoothly generating images for graphics applications or video games, proved to be perfectly suited to parallelising the training of neural networks. In neural network training there are two main stages, forward and back-propagation. During the forward process, images enter the network and pass through successive layers that apply different filters in order to extract salient features and reduce dimensionality. Finally, one or more layers are responsible for the actual classification, detection or segmentation. In backward propagation, the different parameters and weights used by the network are updated, in a process that goes from the output, comparing the obtained and expected output, to the input. The forward process can be parallelised by creating batches of images. Depending on the memory size of the GPUs, copies of the model are created that process all images in a batch in parallel. The larger the batch size we can process, the faster the training will be. This same mechanism is used during the inference process, a process that also allows parallelisation to be used. In recent years, some cloud providers have started to use Tensor Processing Units (TPUs), with certain advantages over GPUs. However, the cost of using these services is often high when performing massive processing.

CARTIF has significant deep neural network training systems, which allows us to solve problems of high computational complexity in a relatively short time. In addition, we have refined several training algorithms using the latest neural networks7 . We have also refined One Shot Learning systems using Siamese networks8. We also use state-of-the-art models in tasks such as object and human recognition, segmentation and detection, image classification, including industrial defects, and human-robot interaction systems using advanced vision algorithms.
1 Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems, 25.
2 Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., … & Fei-Fei, L. (2015). Imagenet large scale visual recognition challenge. International journal of computer vision, 115(3), 211-252.
3 Dai, Z., Liu, H., Le, Q., & Tan, M. (2021). Coatnet: Marrying convolution and attention for all data sizes. Advances in Neural Information Processing Systems, 34.
4 Dodge, S., & Karam, L. (2017, July). A study and comparison of human and deep learning recognition performance under visual distortions. In 2017 26th international conference on computer communication and networks (ICCCN) (pp. 1-7). IEEE.
5 He, K., Gkioxari, G., Dollár, P., & Girshick, R. (2017). Mask r-cnn. In Proceedings of the IEEE international conference on computer vision (pp. 2961-2969).
6 Domingo, J. D., Gómez-García-Bermejo, J., & Zalama, E. (2021). Visual recognition of gymnastic exercise sequences. Application to supervision and robot learning by demonstration. Robotics and Autonomous Systems, 143, 103830.
7 Domingo, J. D., Aparicio, R. M., & Rodrigo, L. M. G. (2022). Cross Validation Voting for Improving CNN Classification in Grocery Products. IEEE Access.
8 Duque Domingo, J., Medina Aparicio, R., & González Rodrigo, L. M. (2021). Improvement of One-Shot-Learning by Integrating a Convolutional Neural Network and an Image Descriptor into a Siamese Neural Network. Applied Sciences, 11(17), 7839.

- Deep Learning in Computer Vision - 18 March 2022