Una red neuronal es un algoritmo que imita el funcionamiento de las neuronas y de las conexiones que hay entre ellas y son entrenadas para que tengan la capacidad de desempeñar una tarea. Se dice que una red neuronal aprende mediante el entrenamiento porque no hay una programación explícita para realizar una tarea, sino que la red se programa sola a partir de ejemplos. Las redes neuronales son el mayor exponente del llamado machine learning o aprendizaje automático.
Las redes neuronales pueden aprender a clasificar y a imitar el comportamiento de sistemas complejos. Si queremos que aprenda a diferenciar entre manzanas y naranjas sólo tenemos que mostrarle unos cuantos ejemplares de ambas frutas y decirle, a la vez, si se trata de una manzana o de una naranja. Una vez entrenada la red neuronal sabrá si está ante una manzana o una naranja. Lo interesante es que lo sabrá aunque las manzanas y naranjas no sean las que se le enseñaron durante el entrenamiento ya que las redes neuronales no memorizan, sino que generalizan. Esa es la clave del aprendizaje de las máquinas.
El interés en las redes neuronales decayó en el cambio de siglo. Por un lado, el mundo empresarial no había visto satisfechas todas sus expectativas y, por otro lado, el mundo académico se centró en algoritmos más prometedores. Sin embargo, algunos investigadores, sobre todo en torno a la Universidad de Montreal, perseveraron en el estudio de las redes neuronales y las hicieron evolucionar hasta lo que llamaron Deep Learning.
El Deep Learning es una serie de algoritmos emparentados con las redes neuronales que tienen la misma finalidad y un rendimiento mayor que otras formas de Machine Learning. La mayor diferencia es la capacidad de abstracción. Volviendo al ejemplo anterior, para clasificar naranjas y manzanas con una red neuronal es necesario extraer características que definan las frutas. Estas características pueden ser el color, la forma, el tamaño, etc. Representar las frutas mediante estas características es una forma de abstracción que debe ser diseñada por la persona que entrene la red neuronal. Pues bien, los algoritmos Deep learning son capaces de realizar una abstracción semejante por sí mismos, sin necesidad de que alguien la diseñe previamente. Por esta razón se dice que el Deep Learningno sólo es capaz de aprender, sino que, además, puede encontrar significado.
El Deep Learning ha aparecido en los medios de comunicación por el interés que han puesto en él grandes empresas y también por la espectacularidad de sus logros tecnológicos. A principios de 2016, los medios dieron noticia de cómo el programa AlphaGo de la empresa Google DeepMind ganó al campeón de goLee Sedol. Esto ha sido un logro técnico sin precedentes, puesto que la estrategia seguida con el ajedrez no puede usarse con el go. Cuando Garry Kasparov perdió al ajedrez en 1996 lo hizo frente a una máquina, la Deep Blue de IBM, programada para calcular todos los posibles movimientos futuros del contrincante. Por el contrario, la máquina de Google DeepMind no está programada para jugar al go, sino que fue enseñada a jugar al go antes de enfrentarse a Lee Sedol. Primero aprendió jugando con el campeón europeo de go y después contra otra versión de sí misma. Partida a partida, la máquina fue mejorando su juego hasta hacerse imbatible.
Grandes empresas como Google o Facebookusan Deep Learning de manera rutinaria en sus productos para reconocer caras y para interpretar el lenguaje natural. También hay empresas pequeñas que ofrecen productos basados en esta tecnología, como Artelnics o Numenta, que pueden aplicarse en muchos procesos industriales. Es de esperar un gran desarrollo de aplicaciones basadas en Deep Learning debido a la necesidad de automatizar el tratamiento inteligente de las enormes cantidades de datos que se generan a diario y, además, porque hay una serie de herramientas open source que ponen estos algoritmos al alcance de todos, como Theano, TensorFlow, H2O u OpenAI Gym .
El éxito de las aplicaciones industriales del Deep Learningdependerá de la disponibilidad de grandes cantidades de datos de calidad, de los recursos de computación disponibles y de su aplicación a problemas apropiados. La detección y clasificación de defectos o averías, el modelado de sistemas para su control y la detección de anomalías podrían ser las primeras aplicaciones prácticas exitosas.
“Por Todos los Santos, a más tardar, el trigo has de sembrar”. “Por Santa Lucía, si sembraras, no cogerías”. Estos refranes recogen el saber popular sobre el mejor momento para realizar la siembra, aunque los agricultores nunca se hayan fiado ciegamente de ellos sino que han hecho uso de su conocimiento para saber cuándo la tierra tiene el tempero necesario para la sementera.
En los tiempos que corren, sin olvidar la perenne exposición a las heladas y sequías intempestivas, la sabiduría popular aplicada a la agricultura se ha visto comprometida por los nuevos cultivos, las nuevas políticas, la mayor competencia por los recursos hídricos, la creciente sensibilización frente al uso de fitosanitarios, por la despoblación del medio rural, la competencia con otros países y las políticas de los que intermedian entre el agricultor y el consumidor. Por todas estas razones, la agricultura se ve sometida a las mismas exigencias de optimización de procesos y mejora del rendimiento que cualquier otra actividad económica.
La optimización y mejora del rendimiento agrícola puede beneficiarse de los avances tecnológicos en los campos de las TIC (tecnologías de la información y comunicaciones) y de IoT (internet de las cosas en sus siglas en inglés). Todas estas tecnologías hacen referencia a la posibilidad de generar, procesar y aprovechar los datos procedentes de un proceso agrícola, generados tanto por sensores como por registros de la actividad.
Cuando se accede a los datos a través de Internet, se procesan en la nube y se consigue algún tipo de autonomía en el proceso hablamos de Internet de las cosas porque, en este caso, tenemos que una parcela, un sistema de riego o una cosechadora están ellas mismas conectadas a Internet, no su operador. Veamos algunos ejemplos.
Un sistema de riego se puede automatizar mediante sensores de humedad enterrados en el suelo. Cuando la medida de la humedad presente en el suelo alcanza un umbral crítico fijado por el agricultor, el sistema de riego se activa automáticamente y está en funcionamiento hasta que se restituye el nivel de humedad óptimo. Si se trata de una parcela grande se puede usar una red de sensores y el sistema de riego puede aplicar diferentes caudales en función de la necesidad de cada parte de la parcela. El sistema se puede perfeccionar si recibe predicciones meteorológicas, ya que si se prevén precipitaciones se puede valorar si merece la pena aplazar el riego. En este caso, el agricultor recibiría la información en su teléfono y tomaría la decisión de activar el sistema de riego o de esperar a la lluvia. Además, la actividad de riego quedaría registrada automáticamente en el sistema de gestión de la finca. En este caso se tiene un sistema de riego que de manera parcialmente autónoma mantiene la humedad necesaria en la tierra consumiendo las cantidades de agua y energía mínimas.
Otro ejemplo podría ser una cosechadora equipada con un sensor capaz de registrar los kilogramos de grano recogidos en cada metro cuadrado. Al finalizar la cosecha se dispondría de un mapa de producción de la parcela que podría ser utilizado en la temporada siguiente por el tractor que se encargue de distribuir abono. Al llegar a los lugares marcados en el mapa como de menor producción, la abonadora aumentaría automáticamente la dosis en una cantidad decidida por el agricultor después de haber estudiado la situación. Además, el momento del abono habría sido decidido de manera automática teniendo en cuenta variables ambientales y su evolución prevista. Esta manera de trabajar permitiría optimizar el uso de abono y registrar automáticamente toda la información en el sistema de gestión de la finca y en el cuaderno de campo, aumentando así el rendimiento agrícola. En el caso de una cooperativa, la información podría ser procesada en la nube, de manera que se pudiera tener un conocimiento exacto de la evolución de la campaña y se pudiera usar esa información para anticiparse a diferentes necesidades y prever el resultado de la cosecha.
Mediante estas técnicas basadas en sensores, en el procesamiento de los datos generados por ellos y en el acceso a las parcelas, máquinas y datos través de internet es posible mejorar el rendimiento de la actividad agrícola y cubrir las lagunas que pudieran haber aparecido en la sabiduría popular.
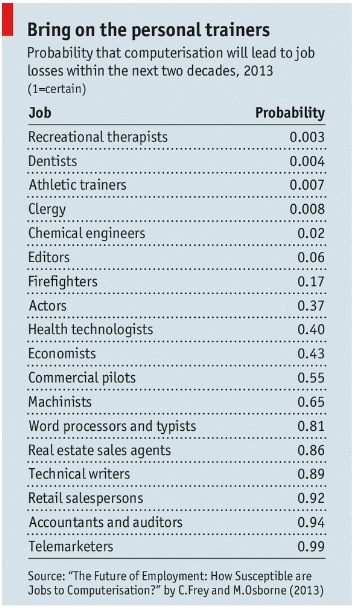
Hay una inquietud creciente generada por los efectos que en la vida de las personas podría tener la inteligencia artificial. Recientemente ha sido el Foro de Davos, el que ha abordado el tema, pero ya en enero de 2014 The Economist hablaba de los empleos que se perderán cuando se generalice esta tecnología.
Todo el mundo está familiarizado con la inteligencia artificial gracias al cine. Lo hemos visto desde Colossus: el proyecto prohibido, en el que un ordenador no sólo llegaba a dominar el mundo, sino que incluso le quitaba la novia a su diseñador, hasta Ex machina, en la que una inteligencia artificial despiadada se abre camino sin ningún tipo de escrúpulo moral para lograr su objetivo, pasando por HAL 9000, la máquina con prioridades morales confundidas. Casi siempre retratada de manera negativa. Sin embargo, la inteligencia artificial que viene no tomará la forma de un androide inquietante, como Ava en Ex Machina, sino que será algo más parecido a HAL 9000. Puede que lo primero que veamos sea la computación cognitiva, materializada en Watson de IBM.
Watson es una máquina que responde preguntas hechas en lenguaje natural capaz de procesar grandes cantidades de información para buscar una respuesta correcta. Se hizo famosa en el año 2008 cuando ganó a dos oponentes humanos en Jeopardy! , un concurso de televisión en el que gana el primero que responda correctamente a una pregunta. Una de sus primeras aplicaciones prácticas, ya comercial, es decidir la mejor combinación de fármacos para el tratamiento del cáncer de pulmón. Otra aplicación que se está gestando es la atención de llamadas telefónicas en call centres. La empresa Genesys, que desarrolla este tipo de sistemas, quiere incorporar Watson a su catálogo. El resultado será que Watson atenderá las llamadas y en algún momento de la conversación decidirá a qué operador humano ha de transferirlas. La experiencia se parecerá a la actual, pero podríamos no llegar a hablar con una persona porque una máquina hará su trabajo, trabajo para el que se requieren habilidades intelectuales.
Capacidades como la de Watson son las que hacen temer la desaparición de todos los puestos de trabajo en los que se realizan actividades intelectuales repetitivas, incluso algunas para las que se requiere cualificación, tales como las que desempeñan contables, ayudantes de abogados, las personas que redactan memorias técnicas o los conductores. Esta situación es comparable a la que se dio cuando apareció la fuerza artificial: máquinas cuya fuerza les permite hacer el trabajo de una docena de hombres pero que son manejadas por uno solo.
La fuerza artificial se ha ido perfeccionando con el desarrollo de la tecnología. Si al principio fue la fuerza del vapor, en la actualidad es la automatización y la robotización de los procesos industriales. La incorporación de la fuerza artificial desplazó a muchos trabajadores, hizo desaparecer oficios pero, a la vez, hizo que aparecieran nuevos puestos de trabajo caracterizados por un nivel formativo mucho más alto. Los trabajadores tuvieron que hacer una transición en la que el cerebro reemplazó al músculo.
Con la llegada de esta inteligencia artificial capaz de realizar las tareas intelectuales repetitivas, ¿cómo tendrá que ser la nueva transición que tendrán que hacer los trabajadores? Tendrá que dirigirse hacia lo que las máquinas, por lo menos hasta que llegue la hard artificial intelligence, no podrán hacer: los trabajos marcados por lo creativo y lo emocional. Sin embargo, es de esperar una etapa de transición compleja, dado que alcanzar el nivel formativo necesario en esta nueva etapa podría no estar al alcance de todo el mundo y, además, las máquinas podrían resultar más baratas para una empresa que la contratación de personas. Todo dependerá del coste de la nueva tecnología. De momento, sólo el hardware de Watson cuesta unos tres millones de dólares, a lo que hay que añadir el software y el mantenimiento.
En cualquier caso, tendremos que hacer la elección de siempre: dejar que otros desarrollen la tecnología y convertirnos en meros usuarios, o adelantarnos al futuro y convertirnos en protagonistas de su desarrollo, bien sea científico, tecnológico o comercial. Una decisión hamletiana que en este país casi siempre hemos tomado mal.
Recientemente los medios de comunicación han informado sobre la opinión apocalíptica de Stephen Hawking, Elon Musk y Bill Gates referente a una posible futura inteligencia artificial que podría llegar a sojuzgar a la Humanidad. Hasta que llegue ese día, y suponiendo que llegue, la tecnología nos ofrece una serie de métodos que remedan algunas capacidades intelectuales humanas y que pueden ser de gran utilidad en la práctica industrial como el aprendizaje no supervisado.
Una de ellas es la posibilidad de que una computadorapueda llegar a darse cuenta, por sí misma y sin conocimiento previo, de las diferentes situaciones o estados que pueden darse en un determinado proceso productivo. Imaginemos una computadora a la que de manera regular le llegan los valores medidos por una serie de sensores colocados en un proceso productivo. Gracias a técnicas de aprendizaje no supervisado, la computadora se dará cuenta de que los datos que le llegan se pueden agrupar en, por ejemplo, tres categorías y además podrá informarnos de cómo se caracteriza cada uno de esos tres grupos. Lo que la computadora no podrá hacer será dar nombre a cada uno de esos tres grupos, a no ser que le ayudemos de alguna manera. Esto es lo que haría una persona que analizara el resultado y se diera cuenta de que esos tres grupos son, por seguir con el ejemplo hipotético, los estados de arranque, marcha y parada. Pero aun con esta limitación, es posible utilizar el aprendizaje no supervisado para detectar averías sin haber registrado nunca ningún caso de ninguna de ellas. A continuación se expone una aplicación desarrollada por CARTIF del aprendizaje no supervisado: la detección de averías sin conocimiento previo de las mismas en un grupo hidroeléctrico.
Un grupo hidroeléctrico es el corazón de una central hidroeléctrica. Su función es transformar en energía eléctrica la energía contenida en un caudal de agua que cae. En cada grupo se miden y registran cientos de variables: tensiones e intensidades eléctricas, temperaturas de partes metálicas, de aceites, de agua de refrigeración, de aire, caudales de agua de refrigeración, de agua turbinada, etc. La situación de partida es un registro de todas esas señales, recogido durante un par de años y sin que conste ninguna avería. El problema consistía en diseñar un sistema que se dé cuenta de que se está produciendo una avería.
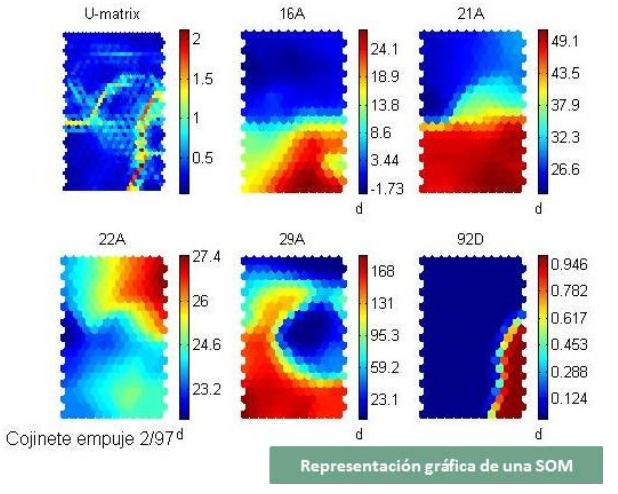
La solución propuesta se basa en un sistema de aprendizaje no supervisado que fue materializado mediante una red neuronal del tipo SOM (Self Organising Map). Esta red neuronal fue alimentada con los datos disponibles y ella sola fue capaz de identificar los posibles estados en los que se podía encontrar el grupo hidroeléctrico. La red neuronal da nombres arbitrarios a cada uno de los estados y debe ser un experto el que los etiquete correctamente. Sin embargo, no es necesario llevar a cabo ese etiquetado para detectar averías a pesar de no haber dispuesto de ningún ejemplo de ninguna de ellas durante el entrenamiento de la red neuronal. Como los datos utilizados para entrenar a la red neuronal no contenían averías y, a la vez, representaban todos los posibles estados de buen funcionamiento del grupo hidroeléctrico, cualquier conjunto de valores medido en él por los sensores y que no encajen en ninguno de los estados identificados corresponderá a una avería. Esta situación se detecta cuando la semejanza entre lo que miden los sensores y los prototipos de funcionamiento almacenados por la red neuronal es demasiado pequeña.
De esta manera nuestra red neuronal fue capaz de detectar una avería de sobrecalentamiento veinte minutos antes de que el sistema de supervisión del grupo hidroeléctrico diera la alarma de que algo iba mal, para lo cual no fue necesario instalar sensores adicionales.
Así que, mientras esperamos el día en el que quizá seamos dominados por las máquinas, quizá podamos aprovecharlas para aplicar algoritmos inteligentes que mejoren la supervisión de los procesos industriales sin requerir de grandes inversiones.