
Deep Learning en Visión Artificial
La visión artificial es una disciplina que ha permitido controlar distintos procesos productivos en la industria y otros sectores desde hace muchos años. Acciones tan habituales como el proceso de compra en un supermercado, requieren técnicas de visión como el escaneado de los códigos de barras.
Hasta hace pocos años, muchos problemas no se podían resolver de una manera sencilla con las técnicas de visión clásicas. Identificar personas u objetos situados en diferentes posiciones de las imágenes o clasificar ciertos tipos de defectos industriales no homogéneos resultaban tareas de alta complejidad que, a menudo, no ofrecían resultados precisos.
Los avances en Inteligencia Artificial (IA) han acompañado también al campo de la visión. Mientras que Alan Turing estableció en 1950 el test de Turing, donde una persona y una máquina se situaban detrás de un muro, y otra persona realizaba preguntas intentando descubrir quién era la persona y quién era la máquina, en la visión artificial mediante IA se buscan sistemas capaces de reproducir el comportamiento de los humanos.
Uno de los campos de la IA es el relativo a las redes neuronales. Utilizadas durante décadas, no fue hasta el año 2012 cuando empezaron a jugar un importante papel en el campo de la visión. AlexNet1 , diseñada por Alex Krizhevsky, fue una de las primeras redes que implementó el diseño con filtros de convolución en 8 capas. Años antes se había establecido un campeonato a nivel mundial donde los algoritmos más potentes intentaban clasificar correctamente las imágenes de ImageNet2, una base de datos con 14 millones de imágenes representativas de 1.000 categorías diferentes. Mientras que el mejor de los algoritmos clásicos, que utilizaba SIFT y vectores de Fisher, obtuvo un 50,9% de precisión clasificando las imágenes de ImageNet, AlexNet llevó la precisión a un 63,3%. Este resultado supuso un hito y representó el inicio de la exploración del aprendizaje profundo, también conocido como Deep Learning (DL). Desde el 2012, se ha profundizado mucho en el estudio de las redes neuronales profundas, creando modelos con más de 200 capas de profundidad y llevando la precisión de clasificación de ImageNet a más de un 90% con el modelo CoAtNet3, que integra capas de convolución con capas de atención de una forma inteligente, deepwise.
Volviendo a la relación de los modernos modelos de visión artificial con respecto a la IA, Dodge et al. (2017)4 descubrieron que, las modernas redes neuronales de clasificación de las imágenes de ImageNet cometían menos errores que los propios humanos, algo que muestra que los sistemas informáticos son capaces de hacer tareas mejor y mucho más rápido que las personas.
Entre los problemas más habituales que resuelve la visión artificial mediante IA, podemos encontrar: clasificación de imágenes, detección y segmentación de objetos, reconocimiento de esqueletos (tanto humanos como de objetos), aprendizaje a partir de un caso, re-identificación, etc. Muchos de los problemas se resuelven tanto en dos dimensiones como en 3D.
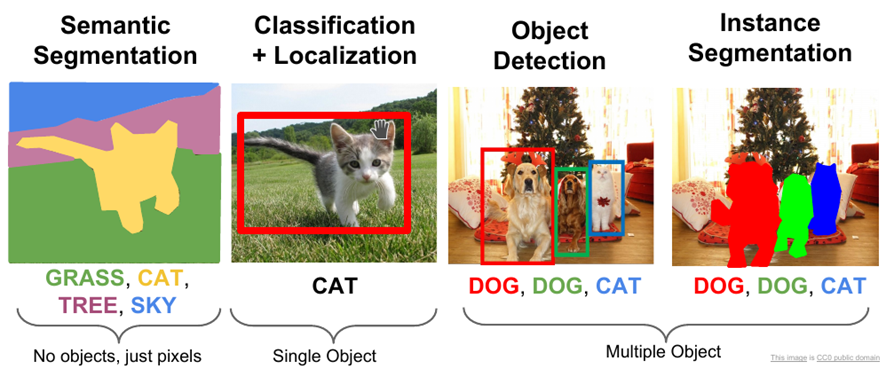
La clasificación simplemente nos indica a qué se corresponde una imagen. Así por ejemplo, un sistema podría decir si una imagen tiene un gato o un perro. La detección de objetos nos permite identificar varios objetos en una imagen y delimitar el rectángulo en el que han sido encontrados. Por ejemplo, podríamos detectar varios perros y gatos. La segmentación permite identificar los límites del objeto, no únicamente un rectángulo. Hay técnicas que permiten segmentar sin conocer qué se está segmentando, y técnicas que permiten segmentar conociendo el tipo de objeto que segmentamos, por ejemplo un gato.
El reconocimiento de esqueletos permite multitud de aplicaciones, que van desde temas relativos a la seguridad hasta el reconocimiento de actividades y su posterior reproducción en un robot. Adicionalmente, existen técnicas que permiten obtener puntos característicos de imágenes, como pueden ser puntos de la cara de una persona, o técnicas para obtener la orientación tridimensional a partir de imágenes 2D.

El aprendizaje a partir de un caso (One Shot Learning) permite que un modelo clasifique imágenes a partir de una única muestra conocida de la clase. Esta técnica, normalmente implementada con redes neuronales siamesas, evita el problema de la necesidad de obtener miles de imágenes de cada clase para entrenar un modelo. De la misma forma, los sistemas de re-identificación son capaces de volver a identificar una persona u objeto a partir de una única imagen.
El alto coste computacional de los modelos de DL llevó desde los primeros momentos a buscar alternativas de cómputo respecto a las CPUs, los procesadores principales de los ordenadores. Las GPU, o unidades de procesamiento gráfico, que originalmente se desarrollaron para llevar a cabo cálculos en paralelo de cara a generar imágenes de aplicaciones gráficas o videojuegos de manera fluida, mostraron que se ajustaban perfectamente a la paralelización del entrenamiento de las redes neuronales. En el entrenamiento de las redes neuronales hay dos etapas principales, el paso hacia adelante (forward) y la propagación hacia atrás (back-propagation). Durante el proceso hacia adelante, las imágenes entran en la red y van pasando a través de sucesivas capas que van aplicando distintos filtros con el fin de extraer las características más destacadas y reducir la dimensionalidad. Finalmente, una o más capas son las responsables de la propia clasificación, detección o segmentación. En la propagación hacia atrás, se actualizan los distintos parámetros y pesos que utiliza la red, en un proceso que va desde la salida, comparando la salida obtenida y esperada, hasta la entrada. El proceso hacia adelante se puede paralelizar creando lotes de imágenes. Dependiendo del tamaño de la memoria de las GPU, se crean copias del modelo que procesan todas las imágenes de un lote en paralelo. Cuanto mayor es el tamaño de lote que podemos procesar, más rápido será el entrenamiento. Este mismo mecanismo es el utilizado durante el proceso de inferencia, proceso que también permite utilizar paralelización. En los últimos años, algunos proveedores de cloud computing han empezado a utilizar Unidades de Proceso Tensorial (TPUs), con ciertas ventajas respecto a las GPU. Sin embargo, el coste de utilización de estos servicios suele ser alto cuando se realiza procesamiento masivo.

CARTIF dispone de importantes sistemas de entrenamiento de redes neuronales profundas, algo que permite resolver problemas de alta complejidad computacional en un tiempo relativamente bajo. Además, hemos perfeccionado diversos algoritmos de entrenamiento utilizando las mas recientes redes neuronales7. También hemos perfeccionado sistemas de aprendizaje a partir de un solo caso mediante redes siamesas8. Así mismo, utilizamos los modelos más avanzados en tareas tales como el reconocimiento, segmentación y detección de objetos y personas, clasificación de imágenes, incluyendo defectos industriales, y sistemas de interacción persona-robot mediante algoritmos avanzados de visión.
1 Krizhevsky. A, Sutskever.I & Hinton.G.E. (2012) Imagenet classification with deep convolutional neural networks, Advances in neural information processing systems, 25
2 Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., … & Fei-Fei, L. (2015). Imagenet large scale visual recognition challenge. International journal of computer vision, 115(3), 211-252.
3 Dai, Z., Liu, H., Le, Q., & Tan, M. (2021). Coatnet: Marrying convolution and attention for all data sizes. Advances in Neural Information Processing Systems, 34.
4 Dodge, S., & Karam, L. (2017, July). A study and comparison of human and deep learning recognition performance under visual distortions. In 2017 26th international conference on computer communication and networks (ICCCN) (pp. 1-7). IEEE.
5 He, K., Gkioxari, G., Dollár, P., & Girshick, R. (2017). Mask r-cnn. In Proceedings of the IEEE international conference on computer vision (pp. 2961-2969).
6 [1] Domingo, J. D., Gómez-García-Bermejo, J., & Zalama, E. (2021). Visual recognition of gymnastic exercise sequences. Application to supervision and robot learning by demonstration. Robotics and Autonomous Systems, 143, 103830.
7 Domingo, J. D., Aparicio, R. M., & Rodrigo, L. M. G. (2022). Cross Validation Voting for Improving CNN Classification in Grocery Products. IEEE Access.
8 Duque Domingo, J., Medina Aparicio, R., & González Rodrigo, L. M. (2021). Improvement of One-Shot-Learning by Integrating a Convolutional Neural Network and an Image Descriptor into a Siamese Neural Network. Applied Sciences, 11(17), 7839.